اگر به یک وب سایت یا فروشگاه رایگان با فضای نامحدود و امکانات فراوان نیاز دارید بی درنگ دکمه زیر را کلیک نمایید.
ایجاد وب سایت یادسته بندی سایت
محبوب ترین ها
پرفروش ترین ها
پر فروش ترین های فورکیا
پر بازدید ترین های فورکیا
 آموزش ساخت بازی بدون دانش برنامه نویسی و طراحی سه بعدی مبتدی تا پیشرفته با نرم افزار
آموزش ساخت بازی بدون دانش برنامه نویسی و طراحی سه بعدی مبتدی تا پیشرفته با نرم افزار دانلود100% رایگان نرم افزار تبلیغات در تلگرام + آموزش کامل و فیلم آموزشی
دانلود100% رایگان نرم افزار تبلیغات در تلگرام + آموزش کامل و فیلم آموزشی کاغذ میلیمتری
کاغذ میلیمتری آموزش افزایش لایک و فالوور واقعی اینستاگرام در اندروید و iOS به صورت نامحدود
آموزش افزایش لایک و فالوور واقعی اینستاگرام در اندروید و iOS به صورت نامحدود اینترنت اشیا-پاورپوینت Internet of Things (IoT) -powerpoint
اینترنت اشیا-پاورپوینت Internet of Things (IoT) -powerpoint آپلود بالا 2 دقیقه اینستاگرام برای اولین بار در فروشگاه دیجی دانلود
آپلود بالا 2 دقیقه اینستاگرام برای اولین بار در فروشگاه دیجی دانلود جلوگیری از هک وای فای + آموزش و نرم افزار
جلوگیری از هک وای فای + آموزش و نرم افزار کتاب راهنمای گام به گام بازی جی تی آی 5 Gta San Andreas
کتاب راهنمای گام به گام بازی جی تی آی 5 Gta San Andreas گام به گام نهم
گام به گام نهم آپدیت پایونیر 7950
آپدیت پایونیر 7950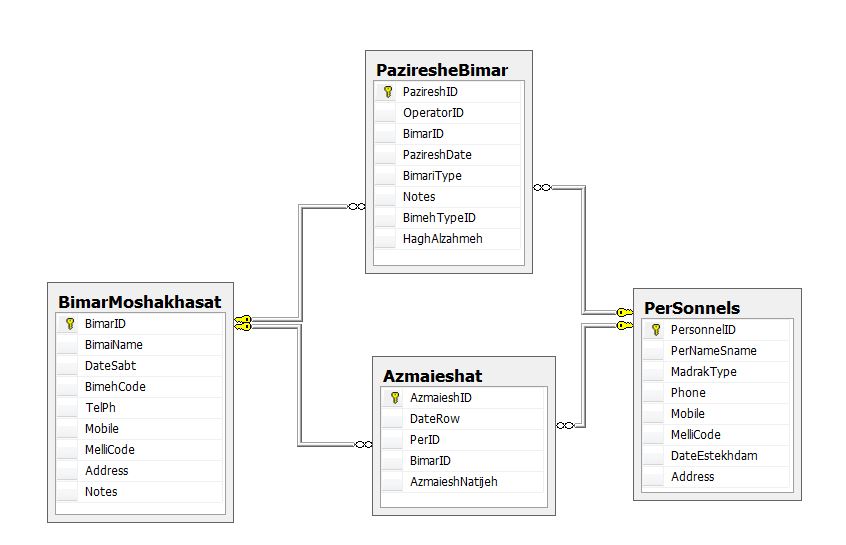 طراحی پایگاه داده مطب پزشک به همراه نمودار ER
طراحی پایگاه داده مطب پزشک به همراه نمودار ER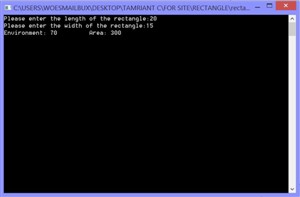 برنامه محاسبه محیط و مساحت مستطیل
برنامه محاسبه محیط و مساحت مستطیل دانلود ارزان کتاب نایاب و گران قیمت (Security+ Guide to Network Security Fundamentals (Cyber Security
دانلود ارزان کتاب نایاب و گران قیمت (Security+ Guide to Network Security Fundamentals (Cyber Security آموزش دانلود و ذخیره تمام موزیک های Spotify در کامپیوتر با فرمت MP3
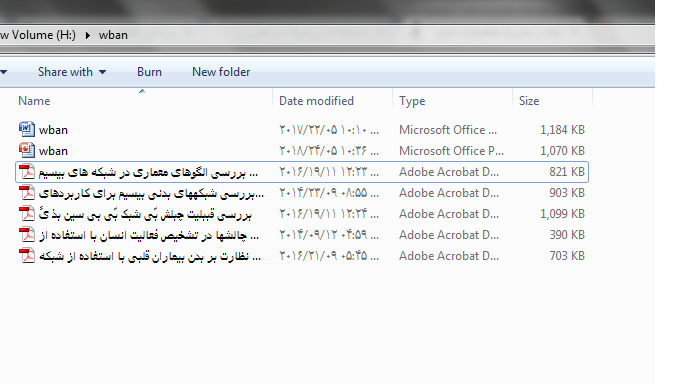
آموزش دانلود و ذخیره تمام موزیک های Spotify در کامپیوتر با فرمت MP3 ICDL2 - سوال کتبی ( سری اول )
ICDL2 - سوال کتبی ( سری اول ) دانلود کتاب کمیاب SQL Injection Attacks and Defense, Second Edition
دانلود کتاب کمیاب SQL Injection Attacks and Defense, Second Edition دانلود کتاب TCPIP Analysis ویژه مدرسین و کسانی که میخواهند TCP IP را مفهومی فراگیری کنند
دانلود کتاب TCPIP Analysis ویژه مدرسین و کسانی که میخواهند TCP IP را مفهومی فراگیری کنند دانلود کتاب آموزش برنامه نویسی Perl
دانلود کتاب آموزش برنامه نویسی Perl دانلود کتاب کاربردی Runnig Linux
دانلود کتاب کاربردی Runnig Linux سوالات مهم در امتحان مهارت های هفت گانه ICDL
سوالات مهم در امتحان مهارت های هفت گانه ICDL دانلود اپرا رایگان برای اندروید جدید و سالم
دانلود اپرا رایگان برای اندروید جدید و سالم دانلود کتاب Python Testing Cookbook
دانلود کتاب Python Testing Cookbook آموزش باز کردن قفل پترن PATTERN گوشی اندروید
آموزش باز کردن قفل پترن PATTERN گوشی اندروید HWz
HWz دانلود کتاب فوق العاده کمیاب و گران قیمت Stealing the Network: How to Own the Box
دانلود کتاب فوق العاده کمیاب و گران قیمت Stealing the Network: How to Own the Box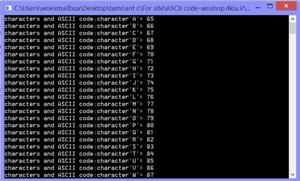 برنامه چاپ کاراکترهای A تا z به همراه کد اسکی آنها
برنامه چاپ کاراکترهای A تا z به همراه کد اسکی آنها پروتکل IPTV مطالعه معماری و پیاده سازی (تخفیف 80% به مدت پنج روز)
پروتکل IPTV مطالعه معماری و پیاده سازی (تخفیف 80% به مدت پنج روز) ICDL2 - سوال کتبی ( سری سوم )
ICDL2 - سوال کتبی ( سری سوم ) دانلود نرم افزار پیدا کردن وبلاگ های رنک دار حذف شده (پیدا کنید بفروشید کسب درآمد کنید)
دانلود نرم افزار پیدا کردن وبلاگ های رنک دار حذف شده (پیدا کنید بفروشید کسب درآمد کنید)برچسب های مهم
پیوند ها
نقش هوش مصنوعی هر روز در زندگی ما بیشتر میشود. آخرین ترند در این زمینه تراشههای هوش مصنوعی و کاربردهای مختلف آنها در گوشیهای هوشمند است. اما شروع توسعهی این تکنولوژی در واقع به خیلی قبلتر برمیگردد؛ یعنی زمانی در دههی ۵۰ میلادی که «دانشگاه دارتموث» (Dartmouth College) در ایالات متحده یک پروژهی تحقیقات تابستانی را به هوش مصنوعی اختصاص داد. ریشههای هوش مصنوعی را حتی میتوان در عمق بیشتری از تاریخ و در فعالیتهای «آلن نیوئل» (Allen Newell)، «هربرت ای. سیمون» (Herbert A. Simon) و «آلن تورینگ» (Alan Turing) جستوجو کرد. آزمون مشهور تورینگ در سال ۱۹۵۰ توسط او در مقالهای مطرح شد. این مقاله یکی از اولین اسنادی است که در آن به وجود آمدن ماشینهای هوشمند پیشبینی شده است. با این حال مقولهی هوش مصنوعی تا پیش از معرفی شدن سوپرکامپیوتر «دیپ بلو» (Deep Blue) توسط کمپانی IBM هنوز توجه جهانیان را به خود جلب نکرده بود. این سوپرکامپیوتر اولین ماشینی بود که توانست قهرمان شطرنج جهان «گری کاسپارف» (Garry Kasparov) را در مسابقهای که در سال ۱۹۹۶ میلادی برگزار شد شکست دهد. الگوریتمهای هوش مصنوعی برای سالهای متمادی است که در دیتاسنترها و کامپیوترهای بزرگ استفاده میشوند، ولی حضور آنها در حوزهی لوازم الکترونیک مصرفی به سالهای اخیر برمیگردد.
تعریف هوش مصنوعی آن را به عنوان شاخهای از علوم کامپیوتر مشخص میکند که با خودکارسازی رفتارهای هوشمندانه سروکار دارد. بخش سخت ماجرا این است: از آنجا که خود هوش را نمیتوانیم به درستی تعریف کنیم، امکان تعریف دقیق هوش مصنوعی هم وجود ندارد. به طور کلی اصطلاح هوش مصنوعی برای تشریح کردن سیستمهایی به کار میرود که هدف آنها استفاده از ماشینها برای تقلید و شبیهسازی هوش انسانی و رفتارهای مرتبط با آن است. این هدف گاه ممکن است با استفاده از الگوریتمهای ساده و الگوهای از پیش تعیین شده محقق شود، ولی گاهی هم نیاز به الگوریتمها فوقالعاده پیچیده دارد.

هوش مصنوعی نمادین (Symbolic) با نمادهایی انتزاعی کار میکند که برای نشان دادن دانش استفاده میشوند. هوش مصنوعی نمادین، هوش مصنوعی کلاسیکی است که بر اساس این ایده کار میکند که تفکر انسان را میتوان در سطحی سلسله مراتبی و منطقی بازسازی کرد. در این روش اطلاعات از بالا با کار کردن روی نمادهای معنیدار برای انسان، ارتباطات انتزاعی و نتیجهگیریهای منطقی پردازش میشوند.
هوش مصنوعی عصبی (Neural AI) در اواخر دههی ۸۰ میلادی در علوم کامپیوتر محبوبیت پیدا کرد. در این گونه، دانش با استفاده از نمادها نمایش داده نمیشود، بلکه به جای آن، نورونهای مصنوعی و ارتباط میان آنها نمایندهی دانش هستند. این هوش مصنوعی چیزی شبیه به یک مغز بازسازی شده است. در این روش دانش کسب شده به قطعاتی کوچکتر (نورونها) خرد و سپس از آن گروههایی متصل به هم تشکیل میشود. این نوع هوش مصنوعی رویکردی پایین به بالا دارد. بر خلاف هوش مصنوعی نمادین، یک سیستم هوش مصنوعی عصبی باید ابتدا آموزش داده شود و در معرض محرکهایی قرار بگیرد تا شبکههای عصبی در آن تجربه کسب کنند، بزرگ شوند و اندوختهی دانش بیشتری داشته باشند.
شبکههای عصبی (Neural Networks) در لایههایی سازماندهی میشوند که با خطوطی شبیهسازی شده به یکدیگر متصل هستند. بالاترین لایه، لایهی دریافت است. این لایه مانند حسگری عمل میکند که اطلاعات را برای پردازش دریافت میکند و آنها را به لایههای پایینتر میفرستد. این فرآیند پس از دریافت اطلاعات با حداقل دو لایهی دیگر (در سیستمهای بزرگ تا بیش از بیست لایه) ادامه پیدا میکند که به صورت سلسه مراتبی روی هم قرار دارند و اطلاعات را با استفاده از پیوندها دستهبندی و ارسال میکنند. در پایینترین بخش سلسله مراتب لایهی خروجی قرار دارد که به طور معمول تعداد نورونهای مصنوعی آن از تمام لایههای دیگر کمتر است. این لایه دادههای محاسبه شده را به فرمتی تبدیل میکند که برای ماشین قابل خواندن باشد.
ابزارها و شیوههای مختلفی برای به کار بردن هوش مصنوعی در دنیای واقعی وجود دارد که برخی از آنها را میتوان در ترکیب با هم استفاده کرد.
اساس کار تمام این روشها «یادگیری ماشینی» (Machine Learning) است. تعریف یادگیری ماشینی سیستمی است که تجربه را به دانش تبدیل میکند. این پروسه به سیستم این توانایی را میدهد که الگوها و قوانین را با سرعتی که همواره در حال افزایش است شناسایی کند. در انواع مختلف یادگیری ماشینی از هر دو نوع هوش مصنوعی نمادین و عصبی استفاده میشود.
یادگیری عمیق (Deep Learning) زیرگونهای از یادگیری ماشینی است که اهمیت آن رو به افزایش است. در این مورد تنها از هوش مصنوعی عصبی یا همان شبکههای عصبی استفاده میشود. اکثر کاربردهای امروزی هوش مصنوعی بر پایهی یادگیری عمیق هستند. به لطف امکان گسترش دادن سریع طراحی شبکههای عصبی و تبدیل کردن آنها به سیستمهایی پیچیدهتر و قویتر با لایههای جدید، مقیاس یادگیری عمیق را میتوان به سادگی تغییر داد و آن را با کاربردهای بسیار زیادی منطبق کرد.

سه نوع پروسهی یادگیری برای آموزش دادن شبکههای عصبی وجود دارد: تحت نظارت، بدون نظارت و یادگیری تقویتی. این سه پروسه روشهای متفاوت زیادی را مهیا میکنند تا بتوان نحوهی تبدیل ورودی به خروجی دلخواه را تنظیم کرد. در یادگیری تحت نظارت، ارزشها و پارامترها از بیرون برای سیستم مشخص میشود، ولی در یادگیری بدون نظارت این خود سیستم است که تلاش میکند الگوهایی را در اطلاعات ورودی کشف کند که ساختاری قابل تشخیص دارند و میتوان آنها را بازتولید کرد. در یادگیری تقویتی هم ماشین به صورت مستقل کار میکند، ولی بر اساس موفقیت یا شکست، تشویق یا تنبیه میشود.
همین الان هم از هوش مصنوعی در بسیاری جاها استفاده میشود، ولی به هیچ وجه همهی این کاربردها در نگاه اول آشکار نیستند. بنابراین انتخاب کردن موقعیتهایی که از امکانات این تکنولوژی در آنها بهره برده میشود، لزوما به تشکیل فهرستی کامل نمیانجامد.
مکانیزمهای هوش مصنوعی برای تشخیص، شناسایی و دستهبندی اشیا و افراد در عکسها ویدیوها بسیار کارآمد هستند. برای رسیدن به این هدف، از مکانیزم ساده ولی سنگین تشخیص الگو استفاده میشود. اگر اطلاعات تصویر رمزگذاری نشده باشد و ماشین بتواند آنها را بخواند، عکسها و ویدیوها را به سادگی میتوان با این روش در دستههای مختلفی قرار داد که امکان جستوجو و یافتن آنها وجود دارد. چنین تشخیصهایی را همچنین میتوان برای اطلاعات صوتی هم به کار برد.
استفاده از چتباتها در بخش خدمات مشتریان روز به روز بیشتر میشود. این دستیارهای مبتنی بر متن، کار خود را با استفاده از تشخیص کلمات کلیدی در درخواست مشتری و نشان دادن واکنش متناسب با آن انجام میدهند. با توجه به کاربردهای مختلف، این نوع دستیارها میتوانند سادهتر یا پیچیدهتر باشند.
تجزیه و تحلیل نظرات علاوه بر پیشبینی نتایج انتخابات در عالم سیاست، در بازاریابی و بسیاری حوزههای دیگر هم استفاده میشود. «استخراج نظرات» (Opinion Mining) که همچنین با نام «تجزیه و تحلیل احساسات» (Sentiment Analysis) هم از آن یاد میشود، برای جستوجو کردن اینترنت در مورد عقاید و عبارات احساسی به کار میرود. با این روشها میتوان نظرسنجیهایی را به صورت ناشناس برگزار کرد.
الگوریتمهای جستوجو مانند الگوریتمهایی که گوگل استفاده میکند، طبیعتا به شدت محرمانه هستند. روشهای محاسبه، رتبهبندی و نمایش نتایج جستوجو تا حد زیادی بر پایهی مکانیزمهایی کار میکنند که از یادگیری ماشینی در آنها استفاده میشود.
پردازش کلمات یا بررسی کردن یک متن از نظر دستور زبان و اشتباهات املایی، یکی از کاربردهای کلاسیک هوش مصنوعی نمادین است که برای مدت زمان زیادی از آن استفاده میشده. در این روش زبان به عنوان شبکهی پیچیدهای از قوانین و دستورالعملها تعریف میشود که قطعات متن را در یک جمله تجزیه و تحلیل میکند و در برخی شرایط میتواند اشتباهات را تشخیص دهد و تصحیح کند. از همین قابلیتها همچنین در تبدیل نوشتار به گفتار در دستیارهای صوتی مانند سیری، الکسا و گوگل اسیستنت هم استفاده میشود.
برچسب های مهم
داده (data) دارای تعاريف مختلفی است، به طور کلی داده ها كلمات و ارزش هاي واقعي هستند كه از طريق مشاهده و تحقيق بدست مي آيند، به عبارت ديگر داده نمودي از وقايع، معلومات، رخدادها، پديده ها و مفاهيم مي باشد.
در محاسبات، داده به اطلاعي گفته می شود که به شکلی مناسب براي انتقال و پردازش ترجمه شود. در کامپيوتر و رسانه های ارتباطاتی امروزی داده به شکل باينری تبديل مي شود. بنابراين داده يک نمايش باينری از يک موجوديت منطقي ذخيره شده در حافظه کامپيوتر است.
از نظر ساختاري داده به مقادير صفت خاصه انواع موجوديت ها اتلاق می شود.
ريشه کلمه داده از عبارت لاتين datum گرفته شده که به معنی اطلاع است. و data فرم جمع آن است. اما datum بندرت استفاده می شود و اکثرا ترجيح می دهند data را به صورت يک کلمه مفرد استفاده کنند.
اطلاع (information) مفهومي است که براي گيرنده آن قابل درک بوده و با دانستن آن می تواند برای حل يک مسئله تصميم گيري يا ارزيابی كند.
وقتي اطلاع وارد کامپيوتر شده ذخيره مي گردد به داده تبديل می شود. بعد از پردازش، داده خروجي مجددا به عنوان اطلاع دريافت مي شود.
وقتي اسم صفت خاصه و مقدار منسوب به آن در دست باشند اطلاعي در مورد موجوديت حاصل مي شود.
هنگاميکه اطلاعات در يک بسته خاص قرار می گيرند و براي درک موضوعی يا انجام کاری استفاده مي شود به دانش (knowledge) تبديل می شود.
موجوديت (entity) مفهوم کلي پديده، شيء يا فردي است که در مورد آن مي خواهيم اطلاع داشته باشيم و در کامپيوتر ذخيره کنيم.
هر نوع موجوديت دارای مجموعه اي از صفات خاصه (attribute) است که ويژگي جداکننده يک نوع موجوديت از نوع ديگر محسوب می شود.
مثال. اگر در نظر داريم يك سيستم پايگاه داده براي يك دبيرستان پياده سازي كنيم مواردي چون دانش آموزان، دبيران، دروس، كلاس ها و غيره جزء موجوديت هاي سيستم به شمار مي روند.
مثال. موجوديت دانشجو در سيستم دانشگاه مي تواند داراي صفات خاصه: نام، نام خاوادگي، سن، سال تولد، رشته تحصيلي، سال ورود و ... باشد و يا موجوديت درس صفات خاصه: كد درس، نام درس و تعداد واحد
يک بانك اطلاعاتي يا پايگاه داده (database) مجموعه اي سازمان يافته و بدون افزونگي از داده های مرتبط به هم است که مي تواند توسط سيستم هاي کاربردي مختلف به اشتراک گذاشته شود و به راحتي دسترسی، مديريت و بهنگام شود.
وقتی داده به صورت پايگاه داده سازماندهی می شود، کاربر و برنامه نويس نيازي به دانستن جزئيات ذخيره سازي داده ندارند. علاوه براين داده مي تواند بدون تاثير روي اجزاي ديگر سيستم تغيير کند. برای مثال از اعداد حقيقي به صحيح، از يک ساختار فايل به ديگری يا از دستگاه ذخيره سازي نوري به مغناطيسي تغيير کند.
ويژگی هائی که داده در پايگاه داده بايد داشته باشند در ليست زير آمده است:
1. اشتراکی شدن (shared)
• داده در پايگاه داده بين چندين کاربر و برنامه کاربردی به اشتراک گذاشته می شود.
2. ماندگاري(persistence)
• وقتي داده در پايگاه داده ذخيره شد پايدار است و از بين نمی رود، مگر آنکه توسط سيستم پايگاه داده تغيير کند.
3. امنيت (security)
• داده در پايگاه داده از فاش شدن، تغيير و تخريب بدون مجوز محافظت می شود. مدير سيستم توسط سطوح دسترسي و قيدهای امنيتی نحوه دستيابی به داده را تعريف می کند و اطمينان می دهد که دستیابی از طريق مناسب انجام می شود.
4. اعتبار (validity)
• يا جامعيت (integrity) و يا صحت(correctness) به درستی داده در پايگاه داده نسبت به موجوديت دنياي واقعي معتبر اشاره دارد. مثلا موجودی بانک نبايد منفی باشد.
5. سازگاری (consistency)
• داده در پايگاه داده با مقدار واقعي داده در دنياي خارج سازگار است. وقتی يک فقره اطلاع در بيش از يک نقطه ذخيره شود و لازم باشد بهنگام شود، اگر بهنگام سازی در همه نقاط انجام نشود ناسازگاری ايجاد می شود.
6. کاهش افزونگی (non redundancy)
• داده در پايگاه داده داراي حداقل افزونگي است. افزونگي به اين معناست که هيچ دو فقره داده در بانک معرف يک موجوديت در دنياي خارج نباشد.
7. استقلال (independence)
• تغييردر نمايش فيزيکی، تکنيک های دستيابی و سازماندهی داده تاثيری روی برنامه های کاربردی ندارد.
دو روش كلي براي ذخيره و بازيابي خودكار داده ها وجود دارد: سيستم فايلی ساده و سيستم پايگاه داده
در اين روش، داده ها در فايل هاي مجزا قرار گرفته و سيستم های جداگانه ای به نام سيستم پردازش فايل براي استفاده از فايل های داده ای طراحي مي شوند. در اين سيستم ها هر برنامه ي كاربردي تنها به فايل داده ای مربوط به خود می تواند مراجعه مي كند.
اشکالات چنين طراحي در ذخيره داده به طور خلاصه عبارتند:
1. افزونگي و ناسازگاري داده به دليل چندين فرمت فايل و تکرار اطلاعات در فايلهاي مختلف.
2. مشکل در دستيابی داده و نياز به نوشتن برنامه جديدي براي انجام هر کار
3. قيدهای جامعيت به جاي اينکه صريحا بيان شوند در کدبرنامه از نظر پنهان مي شد. اضافه کردن قيدهاي جديد يا تغيير قيدهاي موجود به سختي صورت مي گيرد.
4. ايجاد ناسازگاري به دليل وجود چندين کپي از فقره هاي داده
5. مشکلات امنيتی به دليل دسترسي همروند و بدون کنترل توسط چند کاربر
در اين روش كليه داده ها به صورت مجتمع در پايگاه داده ذخيره می شود، ولي هر كاربر ديد خاص خود را نسبت به داده ها دارد. كاربران مختلف مي توانند به طور مشترك با پايگاه داده كار كنند. به دليل تجمع داده افزونگي به حداقل ممكن كاهش مي يابد.
نرم افزاری به نام سيستم مديريت پايگاه داده ( DBMS ) به عنوان واسطه بين برنامه هاي كاربردي و پايگاه داده ايفاي نقش مي كند لذا امنيت داده ها در اين روش بيشتر است.
چند نمونه از کاربردهای سيستم پايگاه داده موارد زير هستند:
• انجام کليه تراکنش های بانکداري
• رزرواسيون و زمانبندي خطوط هوائي
• ثبت نام دانشجويان، واحدگيری و ثبت نمرات در مراکز آموزشی
• ثبت اطلاعات مشتريان، محصولات و فاکتورهای خريد و فروش
• پيگيري سفارشات و پيشنهادات در فروش online
• ثبت رکوردهاي کارمندان و محاسبات حقوق، کسورات مالياتي در سازمان ها
اجزاء اصلي سيستم بانك اطلاعاتي عبارتند از:
1. داده ها
• شامل داده هائي درباره موجوديت هاي مختلف محيط و ارتباط بين موجوديت ها.
2. سخت افزار
• شامل عناصر پردازشی، رسانه های ذخيره سازی داده، دستگاه هاي جانبي، سخت افزارهای ارتباطی و غيره.
3. نرم افزار
• شامل سيستم عامل و نرم افزارهاي ارتباطي شبکه، نرم افزار سيستم مديريت پايگاه داده و برنامه هاي كاربردي.
4. رويه های عملياتی
• شامل کليه عملياتی که روی پايگاه داده انجام می شود، نظير تهيه پشتيبان، آمارگيری و ...
5. کاربر
• شامل كاربران يا كساني كه به نحوي با سيستم در ارتباط هستند نظير مديرپايگاه داده(DBA)، طراحان پايگاه داده (DBD)، برنامه نويسان پايگاه داده (DBP) و کاربران نهائي(end users).
1. تجمع، وحدت ذخيره سازي و کنترل متمرکز داده ها
2. كاهش افزونگي. تجمع داده و وحدت ذخيره سازی باعث کاهش افزونگی می شود. مثلا آدرس های مختلف برای يک مشتری در قسمت های مختلف اداره ثبت نمی شود.
3. به اشتراك گذاشتن داده ها. چند كاربر مي توانند در هم زمان به پايگاه داده دسترسي داشته باشند. برنامه هاي كاربردي موجود قادر به اشتراك گذاردن داده ها در پايگاه داده بوده و برنامه هاي كاربردي جديد نيز مي توانند از اين داده ها استفاده كنند.
4. پرهيز از ناسازگاري. با كاهش افزونگي، كنترل متمرکز و جامعيت، سازگاري و يكپارچگي داده ها تضمين مي شود.
5. اعمال محدوديت هاي امنيتي. سيستم هاي امنيتي در پايگاه داده امكان اعمال كنترل هاي مختلف را براي هر نوع دسترسي ( بازيابي،اصلاح، حذف و غيره) بر روي پايگاه داده فراهم مي كند.
6. صحت بيشتر داده و استقلال از برنامه های کاربردی
7. راحتی پياده سازی برنامه های کاربردی جديد
1. طراحی سيستم های پايگاه داده پيچيده تر، دشوارتر و زمان برتر است.
2. هزينه قابل توجهی صرف سخت افزار و نصب نرم افزار می شود.
3. آسيب ديدن پايگاه داده روی کليه برنامه های کاربردی تاثير می گذارد.
4. هزينه زياد برای تبديل از سيستم فايلی به سيستم پايگاه داده نياز است.
5. نيازمند تعليم اوليه برنامه نويسان و کاربران و استخدام کارمندان خاص پايگاه داده است.
6. نياز به تهيه چندين کپی پشتيبان از پايگاه داده می باشد.
7. خطاهای برنامه می توانند فاجعه برانگيز باشند.
8. زمان اجرای هر برنامه طولانی تر می شود.
9. بسياروابسته به عمليات سيستم مديريت پايگاه داده است.
برچسب های مهم
در این بحث میخواهیم در مورد مفاهیم اولیه برنامه نویسی فارغ از زبان برنامه نویسی خاص صحبت کنیم. دوستانی که علاقه مند به شروع برنامه نویسی هستند اکثرا به دنبال انتخاب زبان یا نقطه آغاز می گردند. نکته ی قابل توجه این است که زبان انتخابی در ادامه راه یا بازار کار موثر بوده اما فهم اولیه جهت طراحی و نگارش یک برنامه در تمامی زبان ها یکسان است و وابستگی زیادی به زبان انتخابی ندارد.
این مطلب برای دوستانی که علاقه مندند بصورت مبتدی برنامه نویسی را آغاز کنند مناسب است. همچنین سعی بر این است که اصطلاحات در بخش ها و مثال های مختلفی توضیح داده شوند.
امید که در این راه موفق باشیم. نظرات سازنده ی شما ما را برای رسیدن به این هدف یاری خواهد کرد.
اجازه دهید با یک مثال روزمره بحث را آغاز کنیم. فرض کنید که میخواهید برای تولد دوستتان کادویی تهیه کنید. در ابتدا تصمیم میگیرید که از منزل خارج شوید و به بازار جهت تهیه کادو بروید. از منزل خارج میشوید و به دنیا سلام میکنید! ، پس از رفتن به بازار انتخاب های زیادی وجود دارد، شما به یک مغازه عطر فروشی میروید و حدود قیمت را به فروشنده میدهید. فروشنده چندین عطر را برای شما می آورد و شما پس از بوییدن چندین عطر یکی را انتخاب میکنید. قیمت دقیق را پرسیده و پس از حساب کردن پول عطر آن را خریداری کرده و به منزل بر میگردید.
حال بیایید مثال بالا را به صورت یک کد برنامه نویسی بررسی کنیم. همانطور که دیدید این اتفاق از یک شروع و یک پایان تشکیل شده است. شما از خانه بیرون آمده اید و در انتها به خانه برگشته اید. در هر زبان برنامه نویسی آغاز و پایان باید تعیین شود. بسته به زبان برنامه نویسی روال شروع و پایان متفاوت است. در جدول زیر برنامه کوتاه “Hello world” به چند زبان بیان شده است.

Hello World معمولا اولین و ساده ترین کدی است که میتوان نوشت. همانطور که در مثال های بالا میبینید ابتدا و انتها در برخی زبان ها با } { یا عبارات BEGIN و END مشخص شده اند. همچنین مثلا در زبان C از کتابخانه <stdio.h> استفاده شده است.
کتابخانه ها مجموعه ای از دستورات هستند که ما باید در ابتدا به کامپایلر (مبدل کد به زبان ماشین) بگوییم که از چه مجموعه ای از دستورات استفاده خواهیم کرد (در قسمت پیشرفته بیشتر توضیح داده خواهد شد). مثلا در زبان C دستور printf که جهت نمایش یک عبارت در خط فرمان مانیتور مورد استفاده قرار میگیرد در کتابخانه <stdio.h> قرار دارد.
همانطور که میبینید در جدول بالا مدل نوشتار جهت رسیدن به نمایش “سلام دنیا” در زبان های مختلف متفاوت است. این نحوه ی نوشتار را اصطلاحا Syntax میگویند. به عنوان مثال Syntax در زبان C به این گونه است که باید برنامه در یک بخش اصلی به اسم Main نوشته شود که آغاز و پایان آن با کروشه باز و بسته تعریف میشود و ته هر خط با علامت ; باید بسته شود ، توجه کنید که دو طرف عبارت Hello World از ” و پرانتز استفاده شده است اما در زبان Python نیازی به پرانتز یا بستن انتهای هر خط نیست. همچنین دستور نمایش یک متن در خروجی برنامه در زبان های مختلف متفاوت است.
برچسب های مهم
اصل جاوا
بسیاری از خصلتهای جاوا بطور مستقیم از این دو زبان C نتیجه مستقیم زبان C++ جاوا به زبان
C++ زبان جاوا از oop است . بسیاری از جنبه های C گرفته شده است . دستور زبان جاوا منتج از دستور زبان
بعاریت گرفته شده است . در حقیقت بسیاری از خصلتهای زبان جاوا از این دو زبان مشتق شده یا با آنها مرتبط است .
علاوه بر این ، تولید جاوا بطور عمیقی متاثر از روال پالایش و تطبیقی است که طی سه دهه گذشته برای زبانهای برنامه
نویسی موجود پیش آمده است . بهمین دلایل بهتر است سیر مراحل و نیروهایی که منجر به تولد جاوا شده را بررسی
نماییم . هرنوع ابتکار و فکر جدید در طراحی زبانها براساس نیاز به پشت سر نهادن یک مشکل اصلی است که زبانهای
قبلی از حل آن عاجز مانده اند . جاوا نیز بهمین ترتیب متولد شد.
برنامه نویسی شی ئ گرا
برنامه نویسی شی ئ گرا هسته اصلی جاوا است . در حقیقت کلیه برنامه های جاوا شی ئ گرا هستند . بر خلاف
آنچنان با زبان جاوا پیوستگی دارند که oop که در آن امکان گزینش شی ئ گرایی وجود دارد . روشهای C++
را فرا گیرید . بهمین دلیل این فصل را با بحث جنبه های oop حتی قبل از نوشتن یک برنامه ساده جاوا نیز باید اصول
آغاز می کنیم . می دانید که کلیه برنامه های کامپیوتری دارای دو عضو هستند : کد و داده . oop نظری
علاوه بر این ، یک برنامه را میتوان بطور نظری حول محور کد یا داده اش سازماندهی نمود . یعنی بعضی برنامه ها حول
محور " آنچه در حال اتفاق است " ( کد ( نوشته شده و سایر برنامه ها حول محور " آنچه تحت تاثیر قرار گرفته است ) "داده ( نوشته می شوند . اینها دو الگوی مختلف ساخت یک برنامه هستند . روش اول را مدل
می نامند . در این روش یک برنامه بعنوان کدهای فعال روی داده (process-oriented model) پردازش گرا
از این مدل بنحو موفقیت آمیزی استفاده می کنند . اما C نظیر (procedural) ها در نظر گرفت . زبانهای رویه ای
همانطوریکه در قسمتهای قبل عنوان شد ، بموازات رشد و گسترش برنامه ها ، این روش منجر به بروز مشکلات بیشتر
و پیچیده تری خواهد شد . برای مدیریت پیچیدگی فزاینده ، دومین روش معروف به برنامه نویسی شی ئ گرا پیشنهاد
شده است . برنامه نویسی شی ئ گرا یک برنامه را حول محور داده های آن یعنی اشیائ و یک مجموعه از رابطها
خوش تعریف برای آن داده ها سازماندهی می کند . یک برنامه شی ئ گرا را می توان بعنوان داده (interfaces)
تلقی نمود . بعدا" خواهید دید (data controlling access to code) های کنترل کننده دسترسی به کدها
با شروع بکار واحد داده های کنترل کننده بسیاری ازمزایای این نوع سازماندهی نصیب شما خواهد شد .
چرا نام جاوا ؟
متولد شد. این پروژه در ابتدا پروژه سبز نام داشت . Sun Micro Systems در سال 1991 میلادی در شرکت
بود که در سال 92 ایجاد oak به عهده داشت. نتیجه کار بر این پروژه زبان James Gosling سرپرستی پروژه را
به معنای بلوط است و زمانی که جیمز از پنجره اتاق کارش به یک درخت بلوط نگاه می کرد، این نام را .oak شد
تصمیم گرفت نامی بهتر برای محصول خود برگزیند . بنابراین اف راد تیم پروژه Sun برگزید؛ اما پس از مدتی شرکت
سبز به یک کافی شاپ نزدیک شرکت رفتند، تا نامی دیگر برای این زبان انتخاب کنند . پس از نصف روز بحث و
Andy bechtolsheim و Arthur Van hoff ،James Gosling که مخفف نامهای ،JAVA بررسی
است به عنوان نام این زبان انتخاب شد . از آنجا که مراسم نامگذاری در کافی شاپ برگزار شده بود، یک فنجان قهوه
داغ به عنوان نماد جاوا در نظر گرفته شد.
Abstraction تجرید
تجرید یک عنصر ضروری در برنامه نویسی شی ئ گرا است . افراد پیچیدگی ها را با استفاده از تجرید مدیریت می
نمایند . بعنوان نمونه ، مردم درباره اتومبیل هرگز بعنوان مجموعه ای از هزاران قطعات منفک از هم تفکر نمیکنند. آنها
اتومبیل را بعنوان یک شی ئ خوب تعریف شده دارای نوعی رفتار منحصر بفرد تلقی می کنند . این تجرید به مردم
امکان می دهد تا از یک اتومبیل استفاده نموده و به خواربار فروشی بروند ، بدون اینکه نگران پیچیدگی اجزایی باشند
که یک اتومبیل را تشکیل می دهند .
آنها قادرند براحتی جزئیات مربوط به نحوه کار موتور ، سیستم های انتقال و ترمز را نادیده بگیرند . در عوض آنها
مختارند تا از اتومبیل بعنوان یک شی ئ کلی استفاده نمایند.
انجام می (hierarchical) یکی از شیوه های قدرتمند مدیریت تجرید با استفاده از طبقه بندیهای سلسله مراتبی
گیرد . این امر به شما امکان می دهد تا معنی و مفهوم سیستم های پیچیده را کنار گذاشته و آنها را به اجزائ کوچک
قابل مدیریت تقسیم نمایید. از دید بیرونی ، یک اتومبیل یک شی ئ منفرد است . از دید داخلی اتومبیل شامل چندین
زیر سیستم است : فرمان ، ترمزها ، سیستم صوتی ، کمربندهای ایمنی ، سیستم حرارتی ، تلفن سلولی و غیره . هر یک از
این زیر سیستم ها بنوبه خود از واحدهای تخصصی کوچکتری تشکیل شده اند. بعنوان نمونه ، سیستم صوتی اتومبیل
و یا یک پخش صوت است . نکته مهم این است که شما بدین ترتیب بر پیچیدگی CD شامل یک رادیو، یک پخش
اتومبیل ( یا هر سیستم پیچیده دیگر ) با استفاده از تجرید سلسله مراتبی ، فائق می آیید . تجریدهای سلسله مراتبی
سیستم های پیچیده را می توان در مورد برنامه های کامپیوتری نیز پیاده سازی نمود . داده های ی ک برنامه پردازش
گرای سنتی را می توان توسط تجرید اشیائ عضو آن ، منتقل نمود . یک ترتیب از مراحل پردازش را می توان به
مجموعه ای از پیامها بین اشیائ تبدیل نمود. بدین ترتیب ، هر یک از این اشیائ رفتار منحصر بفرد خودش را تعریف
خواهد کرد . می توانید با این اشیائ بعنوان موجودیتهای واقعی رفتار کنید که به پیامهایی که به آنها می گویند چکاری
انجام دهند ، مرتبط و وابسته هستند . این هسته اصلی برنامه نویسی شی ئ گراست . مفاهیم شی ئ گرایی در قلب جاوا
قرار گرفته اند ، همچنانکه پایه اصلی ادراکات بشری نیز هستند. مهم اینست که بفهمید این مفاهیم چگونه در برنامه
های کامپیوتری پیاده سازی می شوند . خواهید دید که برنامه نویسی شی ئ گرا یک نمونه قدرتمند و طبیعی برای
تولید برنامه هایی است که بر تغییرات غیر منتظره فائق آمده و چرخه حیات هر یک از پروژه های نرم افزاری اصلی
( شامل مفهوم سازی ، رشد و سالخوردگی ( را همراهی می کنند . بعنوان نمونه ، هر گاه اشیائ خوش تعریف و
رابطهای تمیز و قابل اطمینان به این اشیائ را در اختیار داشته باشید ، آنگاه بطور دلپذیری میتوانید قسمتهای مختلف
یک سیستم قدیمی تر را بدون ترس جابجا نموده یا بکلی از سیستم خارج نمایید .
oop سه اصل
کلیه زبانهای برنامه نویسی شی ئگرا مکانیسمهایی را در اختیار شما قرار میدهند تا مدل شی ئگرا را پیاده سازی نمایید .
و چند شکلی (inheritance) وراثت (encapsulation) این مدل شامل کپسول سازی
می باشد . اکنون نگاه دقیقتری به این مفاهیم خواهیم داشت . (polymorphism)
encapsulation کپسول سازی
کپسول سازی مکانیسمی است که یک کد و داده مربوط با آن کد را یکجا گرد آوری نموده ( در یک کپسول فرضی
قرار داده ) و کپسول بدست آمده را در مقابل دخالت یا سوئ استفاده های غیر مجاز محافظت می نماید . می توان
درنظر گرفت که کد داده مربوطه را نسبت به دستیابیهای غیرمعمول (wrapper) کپسول سازی را بعنوان یک لفافه
و غیر منتظره سایر کدهای تعریف شده در خارج از لفافه محافظت می کند . دستیابی به کد و داده موجود داخل لفافه
از طریق رابطهای خوب تعریف شده کنترل خواهد شد .در دنیای واقعی ، سیستم انتقال اتوماتیک در یک اتومبیل را
درنظر بگیرید . این سیستم صدها بیت از اطلاعات درباره موتور اتومبیل شما را کپسول سازی می کند : مثل سرعت
حرکت شما ، شیب سطح در حال حرکت و موقعیت اهرم انتقال . شما بعنوان یک کاربر قفط یک راه برای تاثیر نهادن
در این کپسول سازی پیچیده خواهید داشت : بوسیله تغییر اهرم انتقال دهنده ، اما با استفاده از سیگنالهای برگشتی یا
برف پاک کن شیشه جلو ، نمی توانید روی سیستم انتقال قدرت اتومبیل تاثیری بگذارید .
بنابراین دست دنده ( اهرم انتقال دنده ) یک رابط خوب تعریف شده والبته منحصر بفرد برای سیستم انتقال است .
مضاف بر اینکه آنچه درون سیستم انتقال اتفاق می افتد ، تاثیری بر اشیائ خارج از سیستم نخواهد داشت . بعنوان مثال ،
دنده های انتقال ، چراغهای جلو اتومبیل را روشن نمی کنند . از آنجاییکه سیستم انتقال اتوموبیلها کپسول سازی شده ،
دهها تولید کننده اتومبیل قادرند سیستم های انتقال دلخواه خود را طراحی و پیاده سازی نمایند . اما از نقطه نظر کاربر
اتومبیل همه این سیستم ها یکسان کار می کنند. درست همین ایده را می توان در برنامه نویسی کامپیوتر نیز پیاده سازی
نمود . قدرت کدهای کپسول شده در این است که هر کسی می داند چگونه به آنها دسترسی یافته و میتواند صرفنظر از
جزئیات اجرا و بدون ترس از تاثیرات جانبی از آنها استفاده نماید .
انجام می گیرد . اگر چه کلاس با جزئیات بیشتری در این کتاب (class) در جاوا کپسول سازی بر اساس کلاس
بررسی خواهد شد ، اما بحث مختصر بعدی در این مورد سودمند خواهد بود .کلاس توصیف کننده ساختار و رفتاری
( داده و کد ) است که توسط یک مجموعه از اشیائ اشاعه خواهد یافت . هر شی ئ در یک کلاس شامل ساختار و
رفتار تعریف شده توسط همان کلاس است . بهمین دلیل ، به اشیائ گاهی " نمونه هایی از یک کلاس " نیز می
گویند . بنابراین ، یک کلاس یک ساختار منطقی است ، یک شی ئ دارای واقعیت فیزیکی است . وقتی یک کلاس
بوجود می آورید ، در حقیقت کد و داده ای که آن کلاس را تشکیل می دهند ، مشخص می نمایید . این عناصر را
یک کلاس می نامند . (members) اعضائ
یا متغیرهای نمونه (member variables) بطورمشخص ، داده تعریف شده توسط کلاس را بعنوان متغیرهای عضو
member می نامند . کدی که روی آن داده ها عمل می کند را روشهای عضو (instance variables)
و آشنا باشید می دانید که روش در بر نامه C++ و C می نامند . اگر با (methods) یا فقط روشها methods
و می باشد . در برنامه های خوب نوشته شده جاوا روشها C++ و C در زبانهای (function) نویسی جاوا همان تابع
توصیف کننده چگونگی استفاده از متغیرهای عضو هستند . یعنی که رفتار و رابط یک کلاس توسط روشهایی تعریف
می شوند که روی داده های نمونه مربوطه عمل می کنند .
چون هدف یک کلاس پیاده سازی کپسول سازی برای موارد پیچیده است ، روشهایی برای پنهان کردن پیچیدگی
اجزائ در داخل یک کلاس وجود دارد . هر روش یا متغیر داخل یک کلاس ممکن است خصوصی
باشد . رابط عمومی یک کلاس ، معرفی کننده هر چیزی است که کاربران خارج از public یاعمومی private
کلاس نیاز به دانستن آنها دارند . روشها و داده های خصوصی فقط توسط کدهای عضو یک کلاس قابل دسترسی
هستند . بنابراین هر کد دیگری که عضو یک کلاس نباشد، نمی تواند به یک روش خصوصی دسترسی داشته باشد .
چون اعضائ خصوصی یک کلاس ممکن است فقط توسط سایر بخشهای برنامه شما از طریق روشهای عمومی کلاس
قابل دسترسی باشند، می توانید مطمئن باشید که فعل و انفعالات غیر مناسب اتفاق نخواهد افتاد . البته ، این بدان معنی
است که رابط عمومی باید با دقت طراحی شود تا کارکرد داخلی یک کلاس را چندان زیاد برملا نکند .
inheritance وراثت
وراثت رویه ای است که طی آن یک شی ئ ویژگیهای شی ئ دیگری را کسب می کند . این موضوع بسیار اهمیت
دارد زیرا از مفهوم طبقه بندی سلسله مراتبی حمایت می کند . همانطوریکه قبلا" گفتیم ، بسیاری از دانشها توسط طبقه
بندی سلسله مراتبی قابل فهم و مدیریت میشوند .بعنوان مثال سگهای شکاری طلایی یکی از انواع طبقه بندیهای سگها
هستند که بنوبه خود جزئی از کلاس پستانداران خونگرم بوده که در کلاس بزرگتری
تحت عنوان حیوانات قرار می گیرند . بدون استفاده از سلسله مراتب ، باید خصوصیات هر یک از اشیائ ر ا جداگانه
توصیف نمود . اما هنگام استفاده از سلسله مراتب ، برای توصیف یک شی ئ کافی است
کیفیتهایی که آن شی ئ را در کلاس مربوطه منحصر بفرد و متمایز می سازد ، مشخص نمایید . آن شی ئ ممکن است
خصوصیات عمومی را از والدین خود بارث برده باشد .
بدین ترتیب در مکانیسم وراثت ، یک شی ئ می تواند یک نمونه مشخص از یک حالت عمومی تر باشد . اجازه دهید
تا با دقت بیشتری به این رویه نگاه کنیم . بسیاری از افراد، دنیا را بطور طبیعی بعنوان مجموعه ای از اشیائ می دانند که
در یک روش سلسله مراتبی بیکدیگر مرتبط شده اند . نظیر حیوانات ، پستانداران و سگها . اگر بخواهید حیوانات را با
یک روش تجریدی توصیف نمایید ، باید برخی خصوصیات نظیر اندازه ، هوش و نوع اسکلت آنها را مشخص نمایید .
حیوانات همچنین ویژگیهای خاص رفتاری دارند ، آنها تغذیه نموده ، تنفس کرده و می خوابند . این توصیف از
خصوصیات و رفتار را توصیف " کلاس " حیوانات می نامند . اگر بخواهید توصیف یک کلاس مشخصتر از حیوانات
مثل پستانداران داشته باشید .
باید خصوصیات دقیقتری نظیر نوع دندانها و آلات پستانداری را مشخص نمایید . این را یک زیر کلاس
پستانداران گویند . چون پستانداران (super class) از حیوانات و خود حیوانات را کلاس بالای (subclass)
نوعی از حیوانات هستند ، بنابراین کلیه خصوصیات حیوانات را بارث برده اند. یک زیر کلاس ارث برنده درحقیقت
کلیه خصوصیات اجداد خود در سلسله مراتب کلاس را به ارث می برد .
وراثت و کپسول سازی ارتباط دو جانبه و فعل و انفعالی دارند . اگر یک کلاس برخی از خصوصیات را کپسول سازی
کند ، آنگاه هر یک از زیر کلاسها همان خصوصیات بعلاوه برخی ویژگیهای خاص خود را خواهند داشت . همین
مفهوم ساده و کلیدی است که به برنامه نویسی شی ئ گرا امکان داده تا در پیچیدگیها بجای روش هندسی ، بروش
خطی توسعه یابد . یک زیر کلاس جدید کلیه خصوصیات از کلیه اجداد خود را بارث می برد . این امر باعث شده
تافعل و انفعالات غیر قابل پیش بینی صادره از کدهای دیگر موجود در سیستم وجود نداشته باشد .
polymorphism چند شکلی
را می توان برای یک کلاس عمومی از فعالیتها (interface) چند شکلی مفهومی است که بوسیله آن یک رابط
بکار برد . فعالیت مشخص توسط طبیعت دقیق یک حالت تعریف می شود . یک پشته را در نظر بگیرید ( که در آن هر
چیزی که آخر آمده ، ابتدا خارج می شود ) . ممکن است برنامه ای داشته باشید که مستلزم سه نوع پشته باشد . یک
پشته برای مقادیر عدد صحیح ، یکی برای مقادیر اعشاری و یکی هم برای کاراکترها لازم دارید . الگوریتمی که این
پشته ها را اجرا میکند، یکسان است ، اگرچه داده های ذخیره شده در هر یک از این پشته ها متفاوت خواهد بود . در
پشته ایج اد نمایید ، و برای هر (routines) یک زبان شی ئ گرا ، شما باید سه مجموعه متفاوت از روالهای
مجموعه اسامی متفاوت اختیار کنید .اما براساس مفهوم چند شکلی در جاوا میتوانید یک مجموعه کلی از روالهای
پشته را مشخص نمایید که همگی از یک نام استفاده کنند .در حالت کلی مفهوم چند شکلی را می توان با عبارت "
را برای گروهی (generic) یک رابط و چندین روش " توصیف نمود . بدین ترتیب قادر هستید یک رابط ژنریک
از فعالیتهای بهم مرتبط طراحی نمایید . با طراحی یک رابط برای مشخص نمودن یک کلاس عمومی از فعالیتها، می
توان پیچیدگی برنامه ها را کاهش داد. این وظیفه کامپایلر است تا عمل مشخصی ( منظور همان روش است ) را برای
هر یک از حالات مختلف انتخاب نماید . شما بعنوان یک برنامه نویس لازم نیست این انتخاب را بصورت دستی انجام
دهید . شما فقط کافی است رابط کلی را بیاد سپرده و از آن به بهترین وجه ممکن استفاده نمایید .
در مثال مربوط به سگها ، حس بویایی سگ نوعی چند شکلی است . اگر سگ بوی یک گربه را استشمام کند ، پارس
کرده و بدنبال گربه خواهد دوید . اگر سگ بوی غذا را استشمام کند ، بزاق دهانش ترشح کرده و بطرف ظرف غذا
حرکت خواهد کرد . در هر دو حالت این حس بویایی سگ است که فعالیت می کند . تفاوت در آن چیزی است که
استشمام می شود ، یعنی نوع داده ای که به سیستم بویایی سگ وارد می شود . همین مفهوم کلی را می توان در جاوا
پیاده سازی نمود و روشهای متفاوت درون برنامه های جاوا را ساماندهی کرد .
چند شکلی ، کپسول سازی و وراثت در تقابل با یکدیگر کار می کنند هنگامیکه مفاهیم چند شکلی ، کپسولسازی و
وراثت را بطور موثری تلفیق نموده و برای تولید یک محیط برنامه نویسی بکار بریم ، آنگاه برنامه هایی تنومند و
غیر قابل قیاس نسبت به مدلهای رویه گرا خواهیم داشت . یک سلسله مراتب خوب طراحی شده ازکلاسها، پایه ای
است برای استفاده مکرر از کدهایی که برای توسعه و آزمایش آنها وقت و تلاش زیادی صرف نموده اید . کپسول
سازی به شما امکان می دهد تا کدهایی را که به رابط عمومی برای کلاسهای شما بستگی دارند ، بدون شکسته شدن
برای پیاده سازیهای دیگر استفاده نمایید . چند شکلی به شما امکان می دهد تا کدهای تمیز قابل حس ، قابل خواندن و
دارای قابلیت ارتجاعی ایجاد نمایید .
از دو مثالی که تاکنون استفاده شده ، مثال مربوط به اتومبیل کاملا" قدرت طراحی شی ئ گرا را توصیف می کند . از
نقطه نظر وراثت ، سگها دارای قدرت تفکر درباره رفتارها هستند ، اما اتوموبیلها شباهت بیشتری با برنامه های کامپیوتری
دارند . کلیه رانندگان وسائط نقلیه با اتکائ به اصل وراثت انواع مختلفی ( زیر کلاسها ) از وسائط نقلیه را می رانند .
خواه اتومبیل یک مینی بوس مدرسه ، یا یک مرسدس بنز ، یا یک پورشه ، یا یک استیشن خانوادگی باشد ، کمابیش
یکسان عمل کرده ، همگی دارای سیستم انتقال قدرت ، ترمز ، و پدال گاز هستند . بعد از کمی تمرین با دنده های یک
اتومبیل ، اکثر افراد براحتی تفاوت بین یک اتومبیل معمولی با یک اتومبیل دنده اتوماتیک را فرا می گیرند ، زیرا افراد
بطور اساسی کلاس بالا ، یعنی سیستم انتقال را درک می کنند .
افرادی که با اتومبیل سر و کار دارند همواره با جوانب کپسول شده ارتباط دارند . پدالهای گاز و ترمز رابطهایی هستند
که پیچیدگی سیستم های مربوطه را از دید شما پنهان نموده تا بتوانید براحتی و سهولت با این سیستم های پیچیده کار
کنید . پیاده سازی یک موتور ، شیوه های مختلف ترمز و اندازه تایرهای اتومبیل تاثیری بر ارتباط گیری شما با توصیف
کلاس پدالها نخواهند گذاشت.
آخرین خصوصیت ، چند شکلی ، بوسیله توانایی کارخانه های اتومبیل سازی برای اجرای طیف وسیعی از گزینه ها
روی یک وسیله نقلیه منعکس می شود . بعنوان مثال کارخانه ممکن است از سیستم ترمز ضد قفل یا همان ترمزهای
معمولی ، فرمان هیدرولیک یا چرخ دنده ای ، نیز از موتورهای 6،4 ،یا 8 سیلندر استفاده نماید
. در هر حال شما روی پدال ترمز فشار می دهید تا اتومبیل متوقف شود ، فرمان را می چرخانید تا جهت حرکت
اتومبیل را تغییر دهید ، و برای شروع حرکت یا شتاب بخشیدن به حرکت روی پدال گاز فشار می دهید . در این موارد
از یک رابطبرای ایجاد کنترل روی تعداد متفاوتی از عملکردها استفاده شده است
کاملا" مشخص است که استفاده از مفاهیم کپسول سازی ، وراثت و چند شکلی باعث شده تا اجزائمنفک با یکدیگر
ترکیب شده و تشکیل یک شی ئ واحد تحت عنوان اتومبیل را بدهند . همین وضعیت در برنامه های کامپیوتری مشاهده
می شود . بوسیله استفاده از اصول شی ئ گرایی ، قطعات مختلف یک برنامه پیچیده را در کنار هم قرار می دهیم تا
یک برنامه منسجم ، تنومند و کلی حاصل شود در ابتدای این بخش گفتیم که کلیه برنامه نویسان جاوا خواه ناخواه شی
ئ گرا کلیه برنامه نویسان جاوا با مفاهیم کپسول سازی ، وراثت و پلی مورفیسم آشنا خواهند شد.
مروری بر جاوا
نظیر سایر زبانهای برنامه نویسی کامپیوتر ، عناصر و اجزائ جاوا مجرد یا منفک از هم نیستند . این اجزائ در ارتباط
تنگاتنگ با یکدیگر سبب بکار افتادن آن زبان می شوند . این پیوستگی اجزائ در عین حال توصیف یکی از وجوه
خاص این زبان را مشکل می سازد . غالبا" بحث درباره یکی از جوانب این زبان مستلزم داشتن
اطلاعات پیش زمینه در جوانب دیگر است . در قسمتهای بعدی به شما امکان داده برنامه های ساده ای توسط زبان جاوا
نوشته و درک نمایید. جاوا یک زبان کاملا" نوع بندی شده است
در حقیقت بخشی از امنیت و قدرتمندی جاوا ناشی از همین موضوع است . اکنون بینیم که معنای دقیق این موضوع
چیست . اول اینکههر متغیری یک نوع دارد ، هر عبارتی ی ک نوع دارد و بالاخره اینکه هر نوع کاملا " و دقیقا "
خواه بطور مستقیم و صریح یا بوسیله پارامترهایی (assignments) تعریف شده است . دوم اینکه ، کلیه انتسابها
که در فراخوانی روشها عبور می کنند ، از نظر سازگاری انواع کنترل می شوند . بدین ترتیب اجبار خودکار یا تلاق ی
انواع در هم پیچیده نظیر سایر زبانهای برنامه نویسی پیش نخواهد آمد. کامپایلر جاوا کلیه عبارات و پارامترها را کنترل
می کند تا مطمئن شود که انواع ، قابلیت سازگاری بهم را داشته باشند . هر گونه عدم تناسب انواع ، خطاهایی هستند
که باید قبل از اینکه کامپایلر عمل کامپایل نمودن کلاس را پایان دهد ، تصحیح شوند .
و هستید ، بیاد بسپارید که جاوا نسبت به هر زبان دیگری نوع بندی C++ و C نکته : اگر دارای تجربیاتی در زبانهای
و می توانید یک مقدار اعشاری را به یک عدد صحیح نسبت دهید . همچنین C++ و C شده تر است . بعنوان مثال در
کنترل شدید انواع بین یک پارامتر و یک آرگومان انجام نمی گیرد . اما در جاوا این کنترل انجام می C در زبان
گیرد . ممکن است کنترل شدید انواع در جاوا در وهله اول کمی کسل کننده بنظر آید . اما بیاد داشته باشید که اجرای
این امر در بلند مدت سبب کاهش احتمال بروز خطا در کدهای شما
چرا جاوا برای اینترنت اهمیت دارد
اینترنت جاوا را پیشاپیش زبانهای برنامه نویسی قرار داد و در عوض جاو ا تاثیرات پیش برنده ای روی اینترنت داشته
است . دلیل این امر بسیار ساده است : جاوا سبب گسترش فضای حرکت اشیائ بطور آزادانه در فضای الکترونیکی
می شود . در یک شبکه ، دو نوع طبقه بندی وسیع از اشیائ در حال انتقال بین سرویس دهنده و رایانه شخصی شما
و برنامه های فعال (passive) وجود دارد : اطلاعات غیر فعال
خود را مرور می کنید ، در e-mail بعنوان نمونه هنگامیکه پست الکترونیکی (dynamic) . و پویا (active)
حال بررسی داده های غیر فعال هستید . حتی هنگامیکه یک برنامه را گرفته و بار گذاری می کنید ، مادامیکه از آن
برنامه استفاده نکنید کدهای برنامه بعنوان داده های غیر فعال هستند . اما نوع دوم اشیائی که امکان انتقال به رایانه
شخصی شما را دارند ، برنامه های پویا و خود اجرا هستند . چنین برنامه ای اگر چه توسط سرویس دهنده ارائه و انتقال
می یابد ، اما یک عامل فعال روی رایانه سرویس گیرنده است . بعنوان نمونه سرویس دهنده قادر است برنامه ای را
بوجود آورد که اطلاعات و داده های ارسالی توسط سرویس دهنده را نمایش دهد . بهمان اندازه که برنامه های پویا و
شبکه ای شده موردتوجه قرار گرفته اند بهمان نسبت نیز دچار مشکلاتی در زمینه امنیت و قابلیت حمل هستند . قبل از
جاوا ، فضای الکترونیکی شامل فقط نیمی از ورودیهایی بود که اکنون وجود دارند . همانطوریکه خواهید دید ،
جاوادرها رابرای یک شکل جدید از برنامه ها باز نموده است :
(applets) ریز برنامه ها
ریز برنامه ها و برنامه های کاربردی جاوا از جاوا برای تولید دو نوع برنامه می توان استفاده نمود: برنامه های کاربردی
یک برنامه کاربردی برنامه ای است که روی رایانه شما و تحت (applets) . و ریز برنامه ها (applications)
نظارت یک سیستم عامل اجرا می شود . بدین ترتیب یک برنامه کاربردی ایجاد شده توسط جاوا مشابه برنامه های
و خواهد بود . هنگامیکه از جاوا برای تولید برنامه های کاربردی استفاده میکنیم ، C++ و C ایجاد شده توسط
تفاوتهای زیادی بین این زبان و سایر زبانهای برنامه نویسی مشاهده نمی کنیم . اما ویژگی جاوا برای تولید ریز برنامه ها
یک برنامه کاربردی است که برای انتقال و حرکت روی (applet) دارای اهمیت زیادی است . یک ریز برنامه
اینترنت و اجرا توسط یک مرورگر قابل انطباق با جاوا طراحی شده است . یک ریز برنامه در حقیقت یک برنامه
ظریف جاوا است که بطور پویا در سراسر اینترنت قابل بارگذاری باشد ، درست مثل یک تصویر، یک فایل صوتی یا
یک قطعه ویدئویی .تفاوت اصلی در اینست که ریزبرنامه یک برنامه کاربردی هوشمند است و شباهتی با یک تصویر
متحرک یا فایل رسانه ای ندارد . بعبارت دیگر این برنامه قادر به عکس العمل در برابر ورودی کاربر و ایجاد تغییرات
پویا است .
ریز برنامه های جاوا بسیار جالب و هیجان انگیزند و قادرند دو مشکل اصلی یعنی امنیت و قابلیت حمل را پشت سر
بگذارند . قبل از ادامه بحث بهتر است مفهوم اصلی این دو مشکل را بیشتر مورد بررسی قرار دهیم .
امنیت
را بار گذاری می کنید با خطر یک (normal) همانطوریکه خودتان هشیار هستید ، هرگاه که یک برنامه عادی
حمله ویروسی مواجه خواهید شد . قبل از جاوا اکثر کاربران ، برنامه های قابل اجرا را بتناوب گرفته و بارگذاری می
برنامه ها می کردند . با این حال بسیاری از (Scanning) کردند و قبل از اجرا برای ویروس زدایی اقدام به اسکن
این کاربران نسبت به حمله ویروسها به سیستم خود نگران بودند . علاوه بر ویروسها ، نوع دیگری از برنامه های مزاحم
وجود دارند که باید در برابر آنها نیز ایمن ماند . این نوع برنامه ها قادرند اطلاعات خصوصی نظیر شماره کارتهای
اعتباری ،ترازهای حساب بانکی و کلمات عبور برای جستجو درسیستم فایلهای محلی رایانه شما را کشف نموده و
بین رایانه شما و برنامه شبکه ای شده ، بر این (firewall) استفاده نمایند . جاوا توسط ایجاد یک دیواره آتش
مشکلات فائق آمده است .
قابلیت حمل
انواع مختلفی از رایانه ها و سیستم های عامل در سراسر دنیا مورد استفاده قرار می گیرند و بسیاری ازاین سیستم ها با
اینترنت متصل میشوند. برای اینکه برنامه ها بتوانند بطور پویا روی انواع مختلف سیستم ها و محیط های عامل متصل به
اینترنت بارگذاری شوند ، وسائلی برای تولید کدهای اجرایی و قابل حمل مورد نیاز است . همانطوریک ه بزودی
خواهید دید ، همان مکانیسمی که امنیت را بوجود می آورد سبب ایجاد قابلیت حمل نیز خواهد شد .
خصلتهای جاوا
هیچ بحثی درباره اصل و نسب جاوا بدون بررسی خصلتهای آن کامل نخواهد شد . اگر چه امنیت و قابلیت حمل ،
نیروهای اصلی تسریع کننده روند شکل گیری جاوا بودند اما عوامل دیگری هم وجود دارند که در شکل نهایی این
زبان تاثیر داشتند . این ملاحظات کلیدی توسط تیم جاوا در اصطلاحات زیر و بعنوان خصلتهای جاوا معرفی شده اند .
simple • ساده
secure • ایمن
portable • قابل حمل
object-oriented • شی ئ گرا
Robust • قدرتمند
Multithreaded • چند نخ کشی شده
Architecture-neutral • معماری خنثی
Interpreted • تفسیر شده
High-performance • عملکرد سطح بالا
Distributed • توزیع شده
Dynamic • پویا
قبلا" دو تا از این خصلتها را بررسی کرده ایم : ایمن و قابل حمل . اکنون سایر خصلتهای جاوا را یک به یک بررسی
خواهیم نمود .
ساده
جاوا طوری شده که برنامه نویسان حرفه ای بسادگی آن را فراگرفته و بطور موثری بکار می برند . فرض کنیم که شما
تجربیاتی در برنامه نویسی دارید ، آنگاه برای کار با جاوا مشکل زیادی نخواهید داشت . اگر قبلا " با مفاهیم شی ئ
گرایی آشنا شده باشید ، آنگاه آموختن جاوا باز هم آسان تر خواهد شد . از همه بهتر اینکه اگر یک برنامه نویس
و C++ و C باشید ، حرکت بطرف جاوا بسیار راحت انجام می گیرد . چون جاوا دستور زبان C++ مجرب
را بارث برده ، اکثر برنامه نویسان برای کار با جاوا دچار مشکل C++ وهمچنین بسیاری از جوانب شی ئ گرایی
یا در جاوا داخل نشده و یا با روشی آسان تر C++ نخواهند شد . علاوه بر اینکه بسیاری از مفاهیم پیچیده
و خاصیت دیگری در جاوا وجود داردC++ و C و ساده تر مورد استفاده قرار گرفته اند . فراسوی شباهتهای جاوا با
که فراگیری آن را بسیار ساده تر می کند : جاوا تلاش کرده که جنبه های استثنایی و خارق العاده نداشته باشد . در
جاوا ، تعداد اندکی از شیوه های کاملا" توصیف شده برای انجام یک وظیفه وجود دارد .
شی ئ گرا
اگر چه این زبان از اجداد خود تاثیر گرفته ، اما طوری طراحی نشده تا کد منبع آن قابل انطباق با سایر زبانهای برنامه
نویسی باشد . این خاصیت به تیم جاوا اجازه داده تا آزادانه روی یک تخته سنگ حکاکی نمایند . یکی از نتایج این
(objects) آزادی در طراحی ، یک روش تمیز، قابل استفاده و واقعیت گرا برای اشیائ
است . جاوااز بسیاری از محیط های نرم افزاری اولیه براساس اشیائ مواردی را به
تحت عنوان " هر چیزی یک شی . است " و نظریه واقعیت (purist) عاریت گرفته و توازنی بین نظریه لفظ قلمی
گرایی " جلوی راه من قرار نگیر " بوجود آورده است . مدل شی ئ در جاوا بسیار ساده و براحتی قابل گسترش است
بعنوان عملکردهای سطح بالای غیر شی ئ تلقی می (integers) در حالیکه انواع ساده آن نظیر اعداد صحیح
شوند .
قدرتمند
محیط چندگانه روی وب ایجاب کننده تقاضاهای غیر عادی برای برنامه هاست ، زیرا این برنامه ها باید در طیف
وسیعی از سیستم ها اجرا شوند . بدین ترتیب در طراحی جاوا اولویت اول توانایی ایجاد برنامه های قدرتمند بوده
است . برای کسب اطمینان جاوا شما را به تعداد محدودی از نواحی کلیدی محدود می کند تا مجبور شوید اشتباهات
خود را در توسعه برنامه خیلی زود پیدا کنید . در همین حال جاوا شما را از نگرانی درباره بسیاری از اشتباهات رایج
ناشی از خطاهای برنامه نویسی می رهاند . از آنجاییکه جاوا یک زبان کاملا" نوع بندی شده است ، هنگام کامپایل کد
شما را کنترل می کند . اما این زبان کدهای شما را هنگام اجرا نیز کنترل می نماید . در حقیقت بسیاری از اشکالات
هارددیسک به شیار که اغلب در حالتهای حین اجرا ایجاد می شوند ، در جاوا ناممکن شده اند . آگاهی بر اینکه آنچه
شما نوشته اید بصورتی قابل پیش بینی در شرایط متغیر عمل می کند ، یکی از جنبه های
اصلی جاوا است .
برای درک بهتر قدرتمندی جاوا، دو دلیل عمده شکست برنامه ها را درنظر بگیرید :اشتباهات در مدیریت حافظه و
شرایط استثنایی پیش بینی نشده ( یعنی خطاهای حین اجرا . ( مدیریت حافظه در محیطهای برنامه نویسی سنتی یکی از
و برنامه نویس باید بصورت دستی کل حافظه پویا را C++ و C وظایف دشوار و آزار دهنده است . بعنوان نمونه در
تخصیص داده و آزاد نماید . این امر گاه منجر به بروز مشکلاتی می شود . بعنوان نمونه گاهی برنامه نویسان فراموش
می کنند حافظه ای راکه قبلا "تخصیص یافته ، آزاد نمایند . یا از این بدتر ، ممکن است تلاش کنند حافظه ای را که
توسط بخشی از کد ایشان در حال استفاده است ، آزاد نمایند . جاوا بوسیله مدیریت تخصیص حافظه و تخصیص مجدد
حافظه واقعا" این مشکلات را از میان برداشته است . ( در حقیقت تخصیص مجدد کاملا" خودکار انجام می گیرد، زیرا
جاوا یک مجموعه سطل آشغال برای اشیائ غیر قابل استفاده تهیه نموده است . ) شرایط استثنایی در محیط های سنتی
ا اتفاق می افتند و باید توسط ساختارهای بد ترکیب "file not found" اغلب در حالتهایی نظیر " تقسیم بر صفر "یا
object-oriented و زمخت مدیریت شوند . جاوا در این زمینه بوسیله تدارک اداره استثنائات شی ئ گرایی
این مشکل را حل کرده است . در یک برنامه خوش ساخت جاوا، کلیه خطاهای هنگام اجرا توسط برنامه شما مدیریت
خواهد شد .
چند نخ کشی شده
(interactive) جاوا برای تامین نیازمندیهای دنیای واقعی بمنظور ایجاد برنامه های شبکه ای و فعل و انفعالی
طراحی شده است . برای تکمیل این هدف ، جاوا از برنامه نویسی چند نخ کشی حمایت می کند که امکان نوشتن
برنامه هایی به شما میدهد که در آن واحد چندین کار را انجام می دهند . سیستم حین اجرای جاوا ، یک راه حل
ارائه می دهد که (process) زیبا و بسیار ماهرانه برای همزمانی چندین پردازش
امکان ساخت سیستم های فعل و انفعالی که بنرمی اجرا میشوند را بوجود آورده است . راه حل سهل الاستفاده جاو ا
برای چند نخ کشی شده به شما امکان تفکر درباره رفتار خاص برنامه تان ( و نه یک زیر سیستم از چند وظیفه ای ) را
می دهد .
Architecture-Neutral معماری خنثی
یکی از مشغولیتهای اساسی طراحان جاوا موضوع طول و قابلیت حمل کدها بود . یکی از مشکلات اصلی سر راه برنامه
نویسان این است که تضمینی وجود ندارد تا برنامه ای را که امروز می نویسید فردا حتی روی همان ماشین اجرا شود .
ارتقائ سیستم های عامل و پردازنده ها و تغییرات در منابع هسته ای سیستم ممکن است دست بدست هم داده تا یک
برنامه را از کار بیندازند . طراحان جاوا تصمیمات متعدد و دشواری در جاوا و حین اجرا اتخاذ نمودند تا بتوانند این
موقعیت را دگرگون نمایند . هدف آنها عبارت بود از : یکبار بنویسید ، هر جایی ، هر زمان و برای همیشه اجرا کنید .
این هدف تا حد زیادی توسط طراحان جاوا تامین شد .
تفسیر شده و عملکرد سطح بالا
همانطوریکه دیدیم ، جاوا قدرت ایجاد برنامه هایی قابل انطباق با چندین محیط را بوسیله کامپایل کردن یک نوع
معرفی واسطه تحت عنوان کد بایتی پیدا کرده است . این کدها روی هر نوع سیستمی که یک حین اجرای جاوا را
فراهم نماید ، قابل اجرا می باشند . بسیاری از راه حلهای قبلی در زمینه برنامه های چند محیطه سبب کاهش
و از کمبزدها و PERL و،Tcl ،BASIC سطح عملکرد برنامه ها شده بود .سایر سیستم های تفسیر شده نظیر
نیز بخوبی اجرا شود . اگر چه cpu نارساییهای عملکرد رنج می بردند . اما جاوا طوری طراحی شده تا روی انواع
صحت دارد که جاوا تفسیر شده است اما کدهای بایتی جاوا آنچنان دقیق طراحی شده که می توان آنها را بسادگی و
بطور مستقیم به کدهای ماشین خاص شما برای عملکردهای سطح بالا ترجمه نمود . سیستم های حین اجرای جاوا که
این بهینه سازی " درست در زمان " را اجرا می کنند ، سبب از دست رفتن هیچیک از مزایای کدهای مستقل از زیربنا
نخواهد شد. اکنون دیگر عملگرد سطح بالا و زیربناهای متعدد در تناقض با یکدیگر نیستند .
توزیع شده
را تبعیت می کند . در حقیقت ، Tcp/ip جاوا مختص محیط توزیع شده اینترنت طراحی شده زیرا پروتکل های
oak چندان تفاوتی با دستیابی به یک فایل ندارد . روایت اولیه جاوا یعنی URL دستیابی به یک منبع توسط آدرس
دربرگیرنده جنبه هایی برای پیام رسانی آدرسهای داخلی فضای الکترونیکی بود . این امر امکان می داد تا اشیائ روی
دو نوع رایانه متفاوت ، پردازشهای از راه دور را اجرا نمایند . جاوا اخیرا"این رابطها را در یک بسته نرم افزاری بنام
احیائ نموده است . این جنبه یک سطح غیر موازی از تجرد برای (RMI) Remote Method Invocation
برنامه نویس سرویس گیرنده / سرویس دهنده بوجود آورده است .
پویا
همراه برنامه های جاوا، مقادیر قابل توجهی از اطلاعات نوع حین اجرا وجود دارد که برای ممیزی و حل مجدد دستیابی
به اشیائ در زمان اجرا مورد استفاده قرار می گیرند . این امر باعث پیوند پویای کد در یک شیوه مطمئن و متهورانه می
کاملا" قاطع است ، جایی که اجرا بصورت پویا ارتقائ (applet) شود . این مسئله برای قدرتمندی محیط ریز برنامه
The Byte codes جادوی جاوا کدهای بایتی
کلید اصلی جادوی جاوا برای حل مشکل امنیت و قابلیت حمل در این است که خروجی یک کامپایلر جاوا، کدهای
قابل اجرا نیستند، بلکه کدهای بایتی هستند . کد بایتی یک مجموعه کاملا" بهینه شده از دستورالعمل هایی است که
(run- طراحی شده که معادل سیستم حین اجرای (Virtual Machine) برای اجرا توسط یک ماشین مجازی
برای کد بایتی است . این امر ممکن (interpreter) جاوا باشد . یعنی سیستم حین اجرای جاوا یک مفسر time)
به کد قابل اجرا کامپایل می شود . در حقیقت اکثر C++ است تا حدی سبب شگفتی شود. همانطوریکه اطلاع دارید
زبانهای برنامه نویسی مدرن طوری طراحی شده اند که قابل کامپایل نه قابل تفسیر باشند و این امر بلحاظ مسائل اجرایی
است .اما این واقعیت که برنامه های جاوا قابل تفسیر شدن است به حل مشکلات پیوسته با بارگذاری برنامه ها روی
اینترنت کمک می کند . دلیل آن روشن است .
جاوا بگونه ای طراحی شده تا یک زبان قابل تفسیر باشد. از آنجاییکه برنامه های جاوا قبل از آنکه قابل کامپایل باشند
قابل تفسیر هستند، امکان استفاده از آنها در طیف گسترده ای از محیط ها وجود دارد . دلیل آن هم بسیار روشن است .
فقط کافی است تا سیستم حین اجرای جاوا برای هر یک از محیط ها اجرا گردد . هنگامیکه بسته نرم افزاری حین اجرا
برای یک سیستم خاص موجود باشد ، برنامه جاوا روی آن سیستم قابل اجرا خواهد شد . بیاد داشته باشید که اگر چه
جزئیات سیستم حین اجرای جاوا از یک محیط تا محیط دیگر متفاوت است ، اما همه آنها یک کد بایتی جاوا را تفسیر
متصل به اینترنت ، باید روایتهای cpu می کنند . اگر جاوا یک زبان قابل کامپایل می بود ، آنگاه برای هر یک از انواع
مختلفی از جاوا نوشته می شد . این راه حل چندان قابل انطباق نیست. بنابراین "تفسیر" راحتترین شیوه برای ایجاد برنامه
های واقعا" قابل حمل است .
این واقعیت که جاوا یک زبان قابل تفسیراست ، به مسئله امنیت هم کمک میکند .از آنجایی که اجرای هر یک برنامه
های جاوا تحت کنترل سیستم حین اجرا انجام شده سیستم فوق می تواند برنامه را دربرگرفته و مانع تولید اثرات جانبی
خارج از سیستم گردد . همانطوریکه خواهید دید ، مسئله امنیت نیز توسط محدودیت های خاصی که در زبان جاوا
وجود دارد اعمال خواهد شد .
هنگامیکه یک برنامه تفسیر میشود، معمولا" کندتر از زمانی که به کدهای اجرایی کامپایل شود ، اجرا خواهد شد . اما
در مورد جاوا این تفاوت در زمان اجرا چندان زیاد نیست .استفاده از کد بایتی امکان اجرای سریعتر برنامه هارا بوجود
می آورد .یک نکته دیگر : اگر چه جاوا طوری طراحی شده تا تفسیر شود ، اما محدودیتی برای کامپایل کدهای بایتی
آن به کدهای معمولی وجود ندارد . حتی اگر کامپایل پویا به کدهای بایتی اعمال شود ، همچنان جنبه های امنیتی و
قابلیت حمل آن محفوظ می ماند ، زیرا سیستم حین اجرا همچنان درگیر محیط اجرایی می ماند . بسیاری از محیط های
کامپایل نمودن کدهای بایتی به کدهای معمولی "(just in time() حین اجرای جاوا این روش " درست در زمان
می باشند . C++ را مورد استفاده قرار می دهند . چنین عملکردی قابل رقابت با
جاوا یک زبان کاملا" نوع بندی شده است
در حقیقت بخشی از امنیت و قدرتمندی جاوا ناشی از همین موضوع است . اکنون ببینیم که معنای دقیق این موضوع
چیست . اول اینکه هر متغیری یک نوع دارد ، هر عبارتی یک نوع دارد و با لاخره اینکه هر نوع کاملا " و دقیقا "
خواه بطور مستقیم و صریح یا بوسیله پارامترهایی (assignments) تعریف شده است . دوم اینکه ، کلیه انتسابها
که در فراخوانی روشها عبور می کنند ، از نظر سازگاری انواع کنترل می شوند . بدین ترتیب اجبار خودکار یا تلاقی
انواع در هم پیچیده نظیر سایر زبانهای برنامه نویسی پیش نخواهد آمد. کامپایلر جاوا کلیه عبارات و پارامترها را کنترل
می کند تا مطمئن شود که انواع ، قابلیت سازگاری بهم را داشته باشند . هر گونه عدم تناسب انواع ، خطاهایی هستند
که باید قبل از اینکه کامپایلر عمل کامپایل نمودن کلاس را پایان دهد ، تصحیح شوند .
و هستید ، بیاد بسپارید که جاوا نسبت به هر زبان دیگری نوع بندی C++ و C نکته : اگر دارای تجربیاتی در زبانهای
و می توانید یک مقدار اعشاری را به یک عدد صحیح نسبت دهید . همچنین C++ و C شده تر است . بعنوان مثال در
کنترل شدید انواع بین یک پارامتر و یک آرگومان انجام نمی گیرد . C در زبان
اما در جاوا این کنترل انجام می گیرد . ممکن است کنترل شدید انواع در جاوا در وهله اول کمی کسل کننده بنظر
آید . اما بیاد داشته باشید که اجرای این امر در بلند مدت سبب کاهش احتمال بروز خطا در کدهای شما می شود.
و در آخر جاوا :
- ساده
- شىء گرا
(Portable) قابل انتقال
(Distributed) توزیع شده
کارایى بالا
(Interpreted) ترجمه شده
Multithreaded
برچسب های مهم
#include <stdio.h>
#include <conio.h>
#include <iostream.h>
float s,sum;
int j,c;
float sine(float k)
{int i;
s=1.0;
for(i=1;i<=2*j+1;i++)s=s*k/i;
sum=sum+c*s;
c=c*(-1);
return sum;
}
void main(void)
{float a,x,pi,ans;
pi=3.14159265358979323846;
do
{clrscr();
cout<<"
Enter your angle(c):";
cin>>"%f",&a;
if(a>=360)a=a-float(int(a/360)*360);
x=a*pi/180;
sum=0;
c=1;
for(j=0;j<=10;j++)ans=sine(x);
cout<<"
Sine %2.0fC=%5.3f",a,ans;
cout<<"
Do you want to continue(y/n)?";
}while(getch()!=n);
}
Cloud Computing چیست؟
به تکنولوژی ارائه اطلاعات، سخت افزار، نرم افزار و هر منبع اشتراکی در رایانه، از طریق شبکه (مثل اینترنت) رایانش ابری یا محاسبات ابری می گویند.
آیا دنیای کامپیوتر به سمت Cloud می رود؟ آیا در آینده مشکلی در اجرای انواع نرم افزارها با سخت افزار های متفاوت نخواهیم داشت؟
قصد دارم محاسبات ابری را به زبانی ساده برای دوستان و علاقه مندان به فناوری شرح دهم.
آیا تا به حال به این مشکل برنخورده اید که به خاطر سخت افزار ضعیف (مثلا کارت گرافیک) نتوانید یک نرم افزار یا بازی را اجرا کنید؟ و یا اینکه نسخه ای از ویندوز بر روی کامپیوتر شما نصب نشود؟
دنیای فناوری اطلاعات به سمتی می رود که بتواند امکانی را فراهم کند که استفاده از سخت افزارها، نرم افزارها و اطلاعات ناهمگون با کمترین مشکل انجام شود. اما چگونه؟ آیا اصلاً چنین چیزی امکان پذیر است؟ با یک مثال بحث را باز می کنم. یک گوشی موبایل ساده که فقط امکانات ضروری را دارد (مثل نوکیا1100  ) در نظر بگیرید. فرض می کنیم که قصد داریم برای مدتی در دسترس نباشیم و می خواهیم منشی تلفنی تماس های دریافتی ما را ذخیره کند اما گفتیم که گوشی ما خیلی ساده (1100) است و حافظه کافی، قدرت پردازش کافی و امکانات کافی را ندارد. راه حل چیست؟ امروزه اپراتورهای تلفن همراه امکانی به نام صندوق پستی را فراهم کرده اند که فارغ از اینکه گوشی موبایل شما از چه نوعی است شما این امکان را خواهید داشت که منشی تلفنی هم داشته باشید یعنی عملیات ذخیره و پردازش را سخت افزارهای اپراتور تلفن همراه انجام می دهد و شما به خاطر سرویسی که دریافت کرده اید باید مبلغی را بپردازید. شاید این ساده ترین مثال برای درک مفهوم رایانش ابری باشد.
) در نظر بگیرید. فرض می کنیم که قصد داریم برای مدتی در دسترس نباشیم و می خواهیم منشی تلفنی تماس های دریافتی ما را ذخیره کند اما گفتیم که گوشی ما خیلی ساده (1100) است و حافظه کافی، قدرت پردازش کافی و امکانات کافی را ندارد. راه حل چیست؟ امروزه اپراتورهای تلفن همراه امکانی به نام صندوق پستی را فراهم کرده اند که فارغ از اینکه گوشی موبایل شما از چه نوعی است شما این امکان را خواهید داشت که منشی تلفنی هم داشته باشید یعنی عملیات ذخیره و پردازش را سخت افزارهای اپراتور تلفن همراه انجام می دهد و شما به خاطر سرویسی که دریافت کرده اید باید مبلغی را بپردازید. شاید این ساده ترین مثال برای درک مفهوم رایانش ابری باشد.
در محاسبات ابری ذخیره و بازیابی اطلاعات و پردازش در تجهیزات ارائه دهنده کلود انجام می شود و شما از تجهیزاتتان فقط برای ورود درخواست ها و نمایش نتایج استفاده خواهید کرد. بنابراین اگر روزی قصد داشته باشید محاسبات خیلی سنگین انجام دهید اما سخت افزارهای شما قدرت آن را نداشته باشند و یا نیاز به ذخیره سازی حجم زیادی از اطلاعات را داشته باشد اما حافظه شما محدود باشد شما قادر خواهید بود به میزان لازم از ارائه دهندگان خدمات کلود سرویس اجاره کنید و نیازی نیست که این تجهیزات گران قیمت را خریداری کنید.
چند سالی است که شرکت های زیادی فعالیت خودشان را در این زمینه شروع کرده اند اما پیشرو های این تکنولوژی را می توان شرکت های آمازون، گوگل، مایکروسافت، اوراکل، آی بی ام و چند تای دیگر معرفی کرد.جالب است بدانید که مایکروسافت سیستم عامل کلود هم دارد Windows Azure
معرفی چند سرویس کلود:

گوگل درایو: اگر با گوگل درایو کار کرده باشید مفهوم ذخیره سازی ابر را تجربه کرده اید.
دراپ باکس: دراپ باکس هم یکی دیگر از ارائه دهندگان فضا برای ذخیره سازی است.

گوگل داکز: شرکت گوگل با سرویس Google Docs ارائه سرویس های نرم افزاری را هم امکان پذیر کرده است یعنی اگر شما بر روی کامپیوتر خود بسته آفیس را نصب نکرده باشید با Google Docs قادر خواهید بود کارهایی را که با ورد، اکسل و پاورپوینت را انجام می دادید را انجام دهید.

آفیس 365: مایکروسافت آفیس به تنهایی یکه تاز برنامه های اداری است این شرکت در زمینه کلود هم Office 365 را برای این منظور معرفی کرده است.
![]()
زوهو: حیف است از کلود صحبت کنیم و اسمی از ZOHO نبریم این شرکت هندی علاوه بر ارائه برنامه های اداری مانند آفیس، در زمینه مدیریت پروژه، مدیریت ارتباط با مشتری و چندین موضوع دیگر فعالیت دارد.
آنتی ویروس ابری: تقریباً تمامی شرکت های معروف در زمینه آنتی ویروس مثل بیت دیفندر، ایسٍت (نود32)،کسپراسکای، پاندا و ... این قابلت را دارند که به صورت آنلاین کامپیوتر شما را ویروس کشی کنند.

بازی ابری: شرکت های زیادی هستند که به صورت آنلاین به شما اجازه بازی کردن می دهند در حالی که پردازش های مربوط به بازی در کامپیوتر آنها انجام می شود.
هر فناوری مزایا و معایب خاص خودش را دارد. اگرچه محاسبات ابری بسیار جالب به نظر می رسد اما محدودیت ها و معایبی هم دارد.
مزایا:
هزینه های سخت افزاری پایین: شما برای اجرای برنامه ها نیاز به سخت افزار های قدرتمند که گران قیمت هستند ندارید.
هزینه های نرم افزاری کمتر: شما اگر بخواهید نرم افزاری مثل نسخه خانگی و اداری آفیس 2013 را خریداری کنید (منظورم در کشورهایی است که قانون کپی رایت در آنها کامل اجرا می شود) بایستی 140 دلار ناقابل را بپردازید در صورتی که با استفاده از سرویس های کلود که بعضی از آنها رایگان هستند می توانید هزینه های نرم افزاری خود را کاهش دهید و یا اینکه به اندازه مصرفتان هزینه بپردازید.
ارتقای سریعتر و راحت تر: نیازی نیست که شما نرم افزار هایتان را به روز کنید. ارائه دهندگان سرویس ها خودشان زحمت آپدیت کردن را می کشند.
ظرفیت نامحدود ذخیره سازی: شما برای ذخیره سازی در فضای Cloud محدودیتی ندارید و هرچقدر که فضا نیاز داشته باشید می توانید خریداری کنید.
قابلیت اطمینان بیشتر و دسترسی جهانی: در رایانش ابری دیگر شما نگران سوختن هارد و از بین رفتن اطلاعات و مسائلی اینچنین نیستید. همچنین از هر کجای دنیا بخواهید می توانید به اسنادتان دسترسی داشته باشید.
دسترسی گروهی: یکی از مهمترین مزایای Cloud Computing دسترسی گروهی به فایل ها است. یک گروه کاری می توانند به صورت همزمان بر روی یک فایل کار بکنند.
معایب:
اتصال دائم به اینترنت: به یاد داشته باشید که برای داشتن همه مزیت های ذکر شده شما باید به اینترنت متصل باشید.
عدم کارایی با سرعت پایین اینترنت: اگر شما بخواهید امکانات گفته شده را از اینترنت بگیرید باید بگویم که با اینترنت های با پهنای باند کم کلافه می شوید.
امنیت: علی رغم اینکه شرکت های ارائه دهنده ی این خدمات ادعا می کنند که اطلاعات شما را با امنیت بالا نگه می دارند این شائبه وجود دارد که آیا دیگران هم می توانند به اطلاعات شخصی ما دسترسی داشته باشند یا اینکه حریم شخصی ما در فضای ابر رعایت می شود.
امیدوارم توانسته باشم مطالب مفیدی را انتقال داده باشم.
برگرفته شده از MyTeacher.Blog.ir
گرید کامپیوتینگ(Grid Computing) تکنولوژی تسهیم کردن منابع شبکه ها/دامنه های مختلف و ناهمگون و مبتنی بر سرویس دریافتی است. مثالی می آوریم، شما کلید برق را میزنید و لامپ روشن میشود. زدن کلید برق به عنوان درخواست سرویس و روشن شدن لامپ نیز دریافت سرویس است. آیا برای شما به عنوان مصرف کننده سرویس، اهمیتی دارد که این برق در کدام نیروگاه تولید شده است؟! قطعاً نه.
در گرید کامپیوتینگ بجای در اختیار داشتن منابع گران قیمت اختصاصی که معمولاً بخش اعظم ظرفیت آن نیز خالی خواهد ماند، ترجیح داده میشود تا منابع ارزان قیمتی تهیه شده و بین شبکه ها تسهیم گردد. در این صورت به هنگام لود کاری، از ظرفیت خالی منابع سایر شبکه ها استفاده خواهد شد. این تکنولوژی بخصوص در کمپانی های چند ملیتی که در قاره های مختلف دارای Data center هستند مورد استفاده قرار خواهد گرفت چرا که در سایر قاره ها، مراکز داده در خارج از ساعت کاری بوده و ترافیک کاری آنها به حداقل رسیده است پس میتوان از منابع سخت افزاری آنها برای قاره ای که هم اکنون دارای لود کاری بیشینه ای است سود جست
Data mining and proprietary software helps companies depict common patterns and correlations in large data volumes, and transform those into actionable information. For the purpose, top data mining software suites use specific algorithms, artificial intelligence, machine learning, and database statistics. Certain systems will also offer advanced functionalities such as data warehousesand customizable KDD processes, which often have the last say on which application you should choose.
But is the choice indeed simple? Our experts believe there are plenty of factors to consider before investing your money in a proprietary solution. The truth is all data mining systems process information in a different way, and use all sorts of methods to validate results, and selection becomes even more cumbersome when assigned to a person without BI experience. In order to help you narrow the list down to few quality products, we’ve listed the market’s top data mining software you should consider in 2017:


Sisense won our Best Business Intelligence Software Award for 2016
Sisense allows companies of any size and industry to mash up data sets from various sources and build a repository of rich reports that are shared across departments. It was distinguished with our Best Business Intelligence Software Award for 2016 and currently holds the no. 1 spot in the business intelligence category. If you want to test the software the vendor offers a great free trial plans. You can easily sign up for Sisense free trial here.
Designed for non technical users with drag-and-drop ease and widget simplicity, this business intelligence software boasts of a proprietary in-chip technology that powers its engine. It’s built on a 64-bit computer using multi-core CPUs for optimal parallelization capabilities. Generating highly visual reports culled from myriad prepared sources is fast. Users can present reports in different ways by selecting from a plate of visualization widgets to create pie charts, bar graphs, line charts, tabular formats, whatever best suits the purpose. From bird’s eye-view, reports can be clicked to drill down to details for accuracy and a more comprehensive data outlook.

Oracle Data Mining is a representative of the company’s Advanced Analytics Database and a market leader companies use to maximize the potential of their data and make accurate predictions. The system works with a powerful data algorithm to target best customers, and identify both anomalies and cross-selling opportunities. The user can also apply a different predictive model upon need, and customize customer profiles in the desired way. What is really specific about this product is that all of its algorithms are implemented as SQL functions, which means it can mine tables, star schema and transactional data, unstructured and CLOB information, and spatial aggregations.
You can also extend Oracle’s SQL developer with a Data Miner GUI, so that your data scientists can adjust information directly in the database, using a component panel and a graphic drag-and-drop workflow. Developers can also integrate their predictive into applications in order to automate the revelation and distribution of intelligence patterns and predictions.

RapidMiner is an integrated environment dedicated to machine learning and text mining, and one of the best rated predictive analysis systems available on the market. The tool can be used for business intelligence, research, training and education, and application development. Created on an open source model, RapidMiner is offered both on premise, and in private cloud infrastructures, and works with template-based frameworks that accelerate delivery and reduce the number of errors that are common in manual code writing.
The RapidMiner suite consists of three modules: the RapidMiner Studio dedicated to workflow and prediction design, prototyping and validation; the RapidMiner Server used to share and operationalize the predictive models created within the Studio; and the RapidMiner Radoop that simplified predictive analysis. Prior to the analysis, RapidMiner also prepares, optimizes, and cleans data to save you some time.

Microsoft SharePoint is everyone’s first association when speaking of data management, and there is a good reason for that. The system has simply imposed itself with simplified intelligence ever since Microsoft entered the BI market, and is still considered as one of the smartest analytical options for corporate and non-commercial users. The application is web-based, and fully integrated with all Microsoft Office products. While it may not be the most powerful analyzer you can find, SharePoint certainly is the simplest information tool beginners should consider.
SharePoint offers an array of custom development capabilities used to accelerate prototyping of web and line-of-business applications. Developers can integrate it with their data sources and corporate directories using standards like oData, oAuth, and REST. The tool is also packed with information management tools and security considerations, and provides access to multiple development scenarios.
Cognos is IBM’s business intelligence suite used for reporting and data analytics, with several customizable components that make it applicable in all niches and industries: Cognos Connection (the web portal that gathers data and summarizes it in scoreboards and reports), the Query Studio (provides self-service queries used to format data, and create diagrams that answer core business questions), the Report Studio (used to generate accurate management reports via professional or express authoring mode); the Analysis Studio (the part that processes large data sources, understand anomalies, and identify trends); the Event Studio (a notification module that keeps users in line with enterprise events); and Workspace Advanced (the user-friendly interface where you can create all types of personalized documents).
You can also extend IBM Congnos’s functionality with several add-ons, including Go!Office that provides access to metadata and diagrams; Go!Search that conducts a full-text search for content in all documents and reports; and Go!Dashboard where you can find external data sources and use those as additional reporting objects.
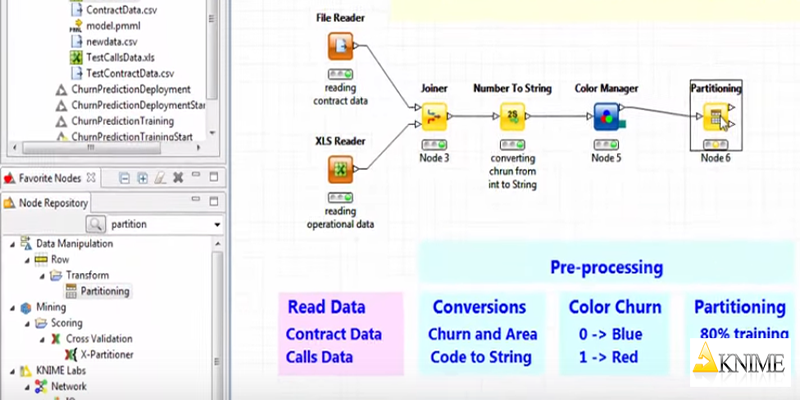
KNIME is an open data analysis platform you can deploy quickly, scale efficiently, and familiarize with in less than no time. In the BI world, KNIME is known as the app that made predictive intelligence accessible to inexperienced users, and one which also has a worldwide users community to share experience with. The data-driven innovation system helps uncover data potential with more than 1000 modules and ready-to-use examples, and an array of integrated tools and algorithms.
KNIME blends all of your data on the same visual platform, but that’s not all the thousands of dedicated users like about it. What is really attractive to them is the arsenal of tool integrations and native nodes that extend the system’s science capacity. Commercial extensions for performance and collaboration are also available.
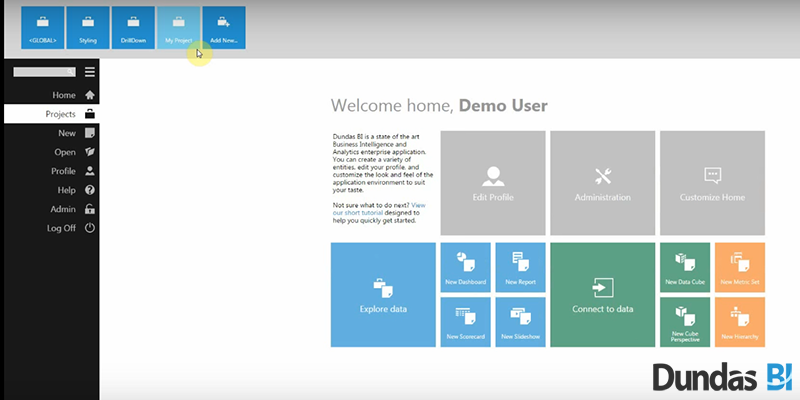
Dundas BI is another top rated data analytics platform known by its superb integrations and fast insights. The system brings together several analytic tools to allow unlimited transformation of industry data, and enriches standard reporting with appealing tables, graphs, and charts. Another thing you will appreciate about it is the gap-free protection of your documents, as well as the possibility to access data from literally any device.
Dundas does more than simply analyzing your data: it structures all pieces in a selective way to make processing easier for you, and links your charts and tables to help you understand what that data means. Thanks to its relational methods, you can perform multidimensional analyses in the blink of an eye, and focus easily on matters that are critical for your business. To make matters even better, Dundas BI helps reduce corporate costs, as it generates reliable reports, and eliminates all need to use additional software.

Board is an intelligence management toolkit recommended by our experts to all companies looking to improve decision making. The platform combines business intelligence and performance management in a single package, collects data from literally any available source, and streamlines reporting letting you extract documents in all preferred formats. The first encounter with the system is likable, to say at least, as Board has one of the most appealing and comprehensive interfaces you will ever see in the BI software industry.
How can Board benefit your business? The system leverages HBMP in-memory technology, which means each of its components works with full steam to boost your performance. Board helps you perform multidimensional analyses with unparalleled simplicity, while it is also able to manage and track all performance planning and control workflows including budgeting, planning and forecasting to profitability analysis. Among other features, Board offers Marketing, HR, and Supply Chain Management solutions.

Orange is a tool that gives dull business analytics the fun vibe they need, which explains why users are fascinated by it. This open source data visualization and machine learning system certainly knows how to streamline widget programming, and help you make smarter decisions without spending hours comparing and analyzing numbers. With Orange, all incoming data is immediately prepared and put in the right format, and then moved where needed with simple widget flips.
Orange is perfect for data visualization – with it, you will understand all box and scatter plots, and statistical distributions, and examine the details of your MDS, heatmaps, hierarchies and linear projections. You can do the same even with multidimensional data, using the tool’s intelligent selections and attribute rankings. Visual Programming is also enabled, and offers fast prototyping, rapid qualitative analysis with clean visualizations, and configurable data connections.

As SAP experts like to put it, Business Objects is the system that can empower your organization’s IQ with around-the-clock access to outstanding BI functionality. Having tested SAP’s quality service ourselves, we see where they’re coming from, and absolutely recommend the tool to all users in need of informed decisions. The system is available both on premise and in cloud, and fully optimized for mobile usage to put information into users’ hands anywhere and anytime.
Why choosing SAP to cater to your BI needs? This flexible and easily scalable platform leverages latest technologies and unites all meaningful data sources, and generates some of the best data visualizations available in the BI industry. You can also use it to depict troubles and opportunities, and captivate audiences with engaging data stories. Its interactive data dashboards, on the other hand, tell a story of their own, making it possible for inexperienced users to understand numbers at a glance. Meaningful reports for the company, customers, and partners are also included in the package, and so are handy integrations used to connect SAP to third-party systems.

Salesforce Analytics Cloud is a reputed intelligence product created to to help medium-sized businesses to large enterprises implement fast, iterative exploration of data, with results displayed via layers of dynamic visualization over underlying data sets. Keeping in line with recent developments, Salesforce Analytics offers full mobile functionality, an affordable pricing scheme with options suitable for small businesses, and flexible deployment options.
How is Salesforce Analytics Cloud better than similar data mining systems? The answer is simple: The system doesn’t only identify trends and anomalies, but detects immediately when and why such happened. It is highly recommended to companies working with sensitive and complex numerical data, as their information will be encrypted and regularly backed up to stop intrusions from causing permanent damage to your business.

There is little chance you’ve researched the BI market and didn’t get acquainted with DOMO, as the company’s innovative policy is praised across all review platforms making competing developers sweat. DOMO is exactly what each data-driven business needs: a single system that derives actionable insights from all data sources, and which you get to use without training.
DOMO offers some of the widest data set and connector support among the tools you will discover on the market, and delivers a unique set of social collaboration features as well. The system makes it possible to combine various data sets with standard SQLs, or to develop personalized model cases combining cloud and local data. For instance, you can easily connect your page view numbers coming from Google Analytics with specific products, and measure its influence. This makes Domo ideal for specific businesses and creative teams, as large as they may be. You should also have in mind the numerous integrations that make DOMO usable in any software ecosystem.
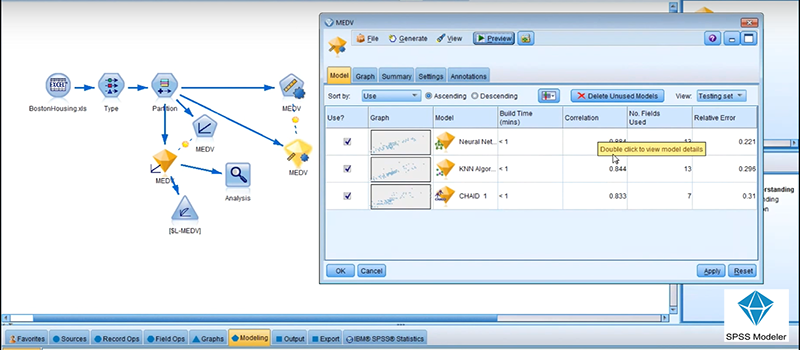
SPSS Modeler is IBM’s prominent predictive analysis and data mining solution that helps companies build predictive models and leverage statistical algorithms without any programming skills. This means that SPSS Modeler eliminates all unnecessary complications raising from data transformation, simplifying at the same time text, entity, and social network analyses. Users get to choose between the company’s Professional and Premium version, depending on whether they need to analyze text in addition to running mainframe data systems and analyzing flat files.
The system integrated spotlessly with Cognos and InfoSphere™ Warehouse to help you maximize the value of your IT investment, as the combination of this three tools help you make accurate future predictions on how the state of your business is going to develop. It also helps improve business outcomes in CRM, marketing, resource planning, risk mitigation, and other areas.

Qlik Sense is a cute BI system that confirms business intelligence doesn’t have to be a dull and unlikable process. Its beautiful and intuitive interface certainly deserves a second look, but so do its advanced features hiding behind it. What our experts like the most about Qlik Sense is that it is equally useful to individuals as it is to large corporations, thanks to the dynamic dashboard that turns data into actionable tool at every turn.
How will Qlik Sense help you become more productive? Qlik Sense’s responsive user experience is built for mobile from the ground up and intelligently adapts visualizations, data, and functionality for the best possible experience on any device including touch. All capabilities of Qlik Sense are available on any device. It also supports robust data integration to transform and combine multiple, disparate data sources and provide seamless analysis across them, including fast calculations, associative exploration, and search. You will also love the Interactive Data Storytelling feature that allows you to use analytics to create and present guided stories, rich with narrative and graphics.
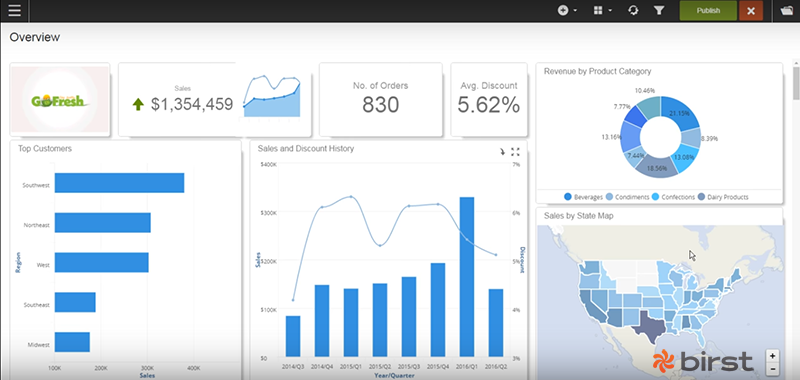
Birst is a cloud-hosted business intelligence solution that handles requirements of both production oriented BI and end-user data visualization and querying. This is called the 2-Tier approach and with Birst, this is possible as it offers data management architecture of the platform. Birst’s software is intended for all business users from IT to marketing to executive management, as it offers features such as responsive and integrated HTML5 dashboards and visual discovery interfaces, automated data refinement, infinite connectivity framework, and many more.
Birst users can painlessly differentiate from their competitors, bring more value to their customers, and generate new revenue streams. However, Birst knows no one can master data exploration at a glance, which is why new and prospective users can easily rely on its experienced tech support team for advice and assistance. Experts will be there for you at any point of time, as you can contact them via phone/email, send a ticket, or make use of their training materials.
در جهان امروز، اطلاعات نقش پول را بازی میکنند. بیشتر دیتاها ساختار بخصوصی ندارند و بدین منظور، شما نیاز به یک متد کارآمد و تاثیرگذار برای استخراج اطلاعات از آنها و تبدیلشان به یک فرمت قابل فهم و قابل استفاده دارید. در این جا است که نقش نرم افزار های داده کاوی پررنگ میشود. این ابزار، علاوه بر توانایی تجزیه و تحلیل های اولیه، میتوانند به مدیریت داده ها بپردازند و با استفاده از پایگاه داده ها، مدل های پردازش داده، تصویرسازی و بروزرسانی آنلاین این ابزار ها میتوانید به خوبی از پس داده کاوی دیتاهای خود بربیایید. ابزار های بسیاری برای این کارها وجود دارند که با استفاده از تکنیک های پیشرفته ای همچون business learning، هوش مصنوعی و machine learning، به کمک شما در داده کاوی می آیند. بیشتر این ابزار ها پولی هستند. ما همچنین دریافته ایم که بیشتر تجارت ها توانایی پرداخت چنین هزینه هنگفتی را برای داده کاوی اطلاعاتشان ندارند؛ به همین دلیل لیستی از ابزار های مجانی داده کاوی را برای شما تهیه کرده ایم که به شما در داده کاوی اطلاعاتتان در راهی بسیار خوب کمک میکنند.

Mply یک نرم افزار machine learning ، بر پایه پایتون میباشد. این برنامه طیف گسترده ای از متدهای ماشین لرنینگ را برای هر دو مشکلات نظارتی و بدون نظارتی به شما ارائه میکند. ویژگی های طبقه بندی، رگرسیون، خوشه چینی، کاهش ابعاد و wavelet submodule در این برنامه گنجانده شده اند.

Jubatus یک کتابخانه و چارچوبی برای یادگیری ماشین آنلاین توزیع شده است. این نرم افزار میتواند از پس صد هزار دیتا در هر ثانیه، با استفاده از سخت افزار مناسب چند شاخه ای بربیاید. Jubatus از طبقه بندی، خوشه بندی، رگرسیون، تجریه و تحلیل و آنالیز گراف پشتیبانی میکند و مدل های جدید معرفی شده را بلافاصله پس از دریافت داده ها بروزرسانی میکند.

PyBrain یک کتابخانه انعطاف پذیر، قدرتمند وابسته به پایتون میباشد. این ابزار شامل الگوریتم هایی برای شبکه های عصبی، یادگیری بدون نظارت (unsupervised learning) ، تکامل و اموزش تقویتی میباشد.

هدف MiningMart، توسعه پردازش های زنجیره ای، توسط تجربه های کاربرانش میباشد. این نرم افزار به منظور توصیف داده ها و اپراتور ها، در زبان متای عملیاتی توسعه یافته است. MiningMart همچنین برای پرونده های KDD نیز توسعه یافته و آماده شده است.

KEEL یک نرم افزار جاوای متن باز، برای دسترسی به الگوریتم های مشکل ساز دیتا ماینینگ همچون خوشه چینی، طبقه بندی، رگرسیون و … میباشد. این نرم فزار با الگویتم های کلاسیک استخراج سازی دانش ، ویژگی های انتخابی، تکنیک های پیش پردازشی، هوش محاسباتی و مدل های هیبریدی همچون شبکه های عصبی تکاملی، سیستم های فازی ژنتیک و غیره بسته بندی و تکمیل شده است.

Fityk یک نرم افزار پردازش داده ها و منحنی ساز میباشد که عمدتا برای انالیز داده ها، از روش chromatography، طیف سنجی فوتوالکترون، powder diffraction، و دیگر تکنیک های تجربی استفاده میکند. علاوه بر اینها، این نرم افزار میتواند برای هر کاری که نیاز مند به منحنی های اطلاعات دو بعدی میباشد استفاده شود.

CMSR data miner یک محیط یکپارچه برای مدل سازی پیش بینی کننده، تصویرسازی اطلاعات، قانون گذاری بر اساس سنجش مدل، قطعه بندی و تحلیل آماری داده ها ارائه میکند. ویژگی های اصلی این نرم افزار شامل خوشه بندی عصبی، امتیاز بندی پایگاه داده (database scoring)، (radial basis function)، hotspot drill down, decision tree classification, Cross-sell Basket Analysis، و غیره میباشند.

Pandas یک کتابخانه قدرت مند و انعطاف پذیر بر اساس پایتون میباشد که قادر به تجزیه و تحلیل داده ها و manipulation میباشد. با استفاده از pandas شما میتوانید به راحتی با اطلاعات از دست رفته کنار بیایید، اطلاعات با شاخص های متفاوت و ناهموار رابه فرم های دیگر تبدیل (convert) کنید و مجموعه داده های بزرگ را ادغام کند یا تغییر شکل دهد. این نرم افزار همچنین از تبدیل فرکانس ها، (moving window linear regressions)، lagging و انتقال داده ها نیز پشتیبانی میکند.

Shogun یک جعبه ی ماشین لرنینگ بزرگ میباشد که متده های ماشین لرنینگ موثر و یکپارچه را ارائه میکند. این نرم افزار با استفاده از ابزار های چند منظوره اش، به شما اجازه میدهد تا کلاس های الگوریتم ها را با یکدیگر ترکیب کرده، و داده های چندگانه را بازنمایی کنید.

SCaVis یک محاسبه گر علمی و تصویر ساز محیطی برای تجزیه و تحلیل داده ها و تجسم سازی آنهاست. این نرم افزار میتواند برای داده های عددی با حجم بالا استفاده شود و بر روی هر پلت فورم جاوایی اجرا شود.

MALLET یک بسته مبتنی بر جاوا برای طبقه بندی اسناد، استخراج اطلاعات، خوشه بندی، مدل سازی موضوع، پردازش زبان طبیعی، ماشین لرنینگ و غیره میباشد. این بسته شامل الگوریتم های متعددی برای عملکرد محاسباتی با استفاده از معیارهای مختلف میباشد. همچنین، یک بسته افزودنی برای این ابزار وجود دارد که GRMM نامیده میشود و شامل پشتیبانی برای مدل های گرافیکی میباشد.

CLUTO یک پکیج نرم افزاری برای خوشه بندی مجموعه داده های کم و زیاد (ابعادی) است. این پکیج از ویژگی دسته بندی چندگانه الگوریتم های خوشه بندی، توابع فاصله دار، اشکال ادغامی، قابلیت تجسم و متد های مختلفی برای خلاصه سازی خوشه ها استفاده میکند.

The databionic ESOM tools مجموعه ای از برنامه ها برای اجرای وظایف داده کاوی همچون clustering, classification و visualizationمیباشد. این مجموعه شامل ویژکی های تعاملی، تجزیه و تحلیل های استثماری داده ها، تصویر سازی متحرک، و غیره (creation of non-redundant U-maps, creation of ESOM classifier, automated application to new data and more) میباشد.

Rattle به شما یک رابط منطقی برای دیتا ماینینگ ارائه میدهد که بر اساس زبان آماری مجانی R (با استفاده از رابط گرافیکی گنوم) کار میکند. هدف اصلی این ابزار، ارائه یک رابط بصری است.

Apache Mahout یک machine learning مقیاس پذیر و پلتفورم داده کاوی میباشد. در اینجا کلمه (مقیاس پذیر) اشاره به مجموعه داده های بزرگ دارد). این ابزار به طور عمده از ۳ مورد ۱- i.e. recommendation mining 2-خوشیه بندی و ۳-طبقه بندی استفاده میکند.

Tanagra یک ابزار داده کاوی برای اهداف علمی و پژوهشی است. این ابزار شامل چندین تکنیک داده کاوی همچون تجزیه و تحلیل داده ها، ماشین لرنینگ، یادگیری آماری و غیره میباشد. این ابزار همچون یک پلتفورم تجربی رفتار میکند تا شما بتوانید متد خودتان را برای مقایسه عملکرد های مختلف به آن اضافه کنید.

PSPP ابزاری است برای آنالیز آماری که در نتیجه پروژه GNU بوجود آمده است. این ابزار از کتابخانه علمی GNU برای محاسبات ریاضی و تولید گراف استفاده میکند. شما در این نرم افزار میتوانید، دو یا چندین پایگاه داده را به صورت همزمان باز، آنالیز، ادیت و ادغام کنید. این نرم افزار از بیش از یک میلیارد متغیر پشتیبانی میکند.

jHepWork، بستری برای تجزیه تحلیل داده ها، انجام محاسبات علمی و مصورسازی میباشد که بر اساس زبان جاوا نوشته شده است و در عین حال با پایتون نیز همکاری میکند. این پلتفورم برای تجزیه و تحلیل های کارآمد تر، قادر به نمایش طرح ها به صورت دو بعدی و سه بعدی میباشد.
![]()
NLTK مخفف جعبه ابزار زبان طبیعی میباشد. این برنامه یک دسته از ابزار های پردازش زبانی همچون دیتا ماینینگ، data scraping، ماشین لرنینگ، تجزیه و تحلیل احساسی و غیره را ارائه میدهد.

Vowpal Wabbit یک پروژه ماشین لرنینگ میباشد که توسط یاهو طراحی شده و در تحقیقات مایکروسافت ارتقا پیدا کرده است تا به ساخت سریع، مفید و مقیاس پذیر الگوریتم های یادگیری کمک کند. این پروژه به خاطر داشتن توانایی یادگیری موازی از دیگر رقیبان خود برتری یافته است.

KNIME یک پلت فورم متن باز یکپارچه داده کاوی است که قادر به انجام هر ۳ مرحله ی داده کاوی (استخراج، انتقال و بارگزاری داده ها) میباشد. KNIME ماژول های مختلف را برای داده کاوی و ماشین لرنینگ، از طریق مفهوم مدولار data pipe-lining با یکدیگر هماهنگ سازی و یکپارچه میکند.

scikit-learn ابزارهای ساده و کارآمدی را برای داده کاوی و آنالیز ارائه میکند. این نرم افزار به صورت متن باز میباشد و از پردازش، طبقه بندی، خوشه بندی، رگرسیون و dimensionality reduction نیز پشتیبانی میکند.

Gephi یک پلتفورم تصویرسازی تعاملی برای سیستم های پیچیده، گراف های مرتبه ای و تمام انواع شبکه ها میباشد، این ابزار بر اساس رابط کاربری NetBeans طراحی شده است و از موتور رندر سه بعدی بهره می برد. همچنین شما میتوانید طرح ها و معیار های خود را از طریق پلاگین های در دسترس، شخصی سازی کنید.

R یک زبان برنامه نویسی و محیطی برای محاسباط آماری و گرافیکی است. این زبان به طور گسترده ای توسط داده کاوان برای تجزیه و تحلیل داده ها و ساخت نرم افزار های آماری استفاده می شود. علاوه بر این، این ابزار از تجزیه و تحلیل های time-series، طبقه بندی، خوشه بندی، مدل سازی خطی و غیر خطی نیز پشتیبانی میکند.

Orange یک ابزار متن باز برای تصویر سازی داده ها و تجزیه تحلیل برای پایه پایتون میباشد. این ابزار همچنین شامل قطعاتی برای ماشین لرنینگ، متن کاوی و bioinformatics میباشد. تا به امروز این ابزار از نمودار های میله ای، درختی، پراکندگی، heatmaps و تجزیه و تحلیل داده ها با بیش از ۱۰۰ ویجهت همراه پشتیبانی کرده است.

Weka مجموعه ای از الگوریتم های ماشین لرنینگ میباشد که برای حل مشکلات داده کاوی طراحی شده اند. این الگوریتم ها میتوانند به طور مستقیم بر روی پایگاه داده ها اعمال شوند، یا از طریق کد های جاوایی که شما وارد میکنید فراخوانده می شوند. این الگوریتم ها میتوانند در بسیاری از اپلیکیشن های مختلف برای نجزیه و تحلیل داده ها، تصویر سازی، مدل سازی پیش بینی کننده و غیره استفاده شوند.

RapidMiner یک پلتفورم داده کاوی مدرن میباشد که روند معنا دار کردن اطلاعات در هم بر هم را در داده کاوی تسریع می بخشد. این پلتفورم با هر محیطی که حاوی اطلاعاتی از هر منبعی میباشد کار میکند و شما میتوانید دیدگاه های خود را در آن پیاده سازی کنید. تنها ایرادی که میتوان به این ابزار گرفت این است که نسخه ی کامل آن مجانی نمیباشد!
سوییچ ها به منظور مسیریابی ترافیک موجود در شبکه از سه روش سوییچینگ استفاده می کنند .
1. Store and forward
2. Cut through
3. Fragment Free

در این روش سوییچ در ابتدا کل بسته اطلاعاتی رو ذخیره میکنه ، سپس به خطایابی اون بسته میپردازه و در صورتی که خطایی در اون بسته پیدا بکنه سریعا اون بسته رو حذف میکنه ولی در صورتی که خطایی پیدا نکرد سوییچ آدرس کارت شبکه گیرنده بسته رو جستجو کرده و بعد از پیدا کردن آدرس کارت شبکه مقصد اون بسته رو به نود مقصد ارسال میکند .
این نوع سوییچ ها برای شبکه های محلی بسیار مناسب هستند چرا که بسته های اطلاعاتی خراب شده رو پاکسازی میکنن و به همین دلیل این سوییچ ها باعث کاهش بروز عمل تصادف یا Coliisions خواهند شد .
این روش ساده ترین روش سوییچینگ است .
پل ها یا هاب ها از این روش فقط استفاده میکنن در صورتی که سوییچ ها از هر سه روش بالا نیز استفاده میکنن .
در این روش سوییچ زمانی که فریمی رو دریافت میکنه ، در ابتدا اون رو در حافظه RAM خود Buffer میکنه و در مرحله بعد آدرس های Source mac و Destination mac رو از هدر فریم خونده ولی قبل از ارسال اون به سمت مقصد ، کد CRC فریم رو از بخش Trailer اون چک میکنه در صورتی که عدد CRC صحیح بود ، سوییچ فریم رو به سمت مقصد ارسال میکنه و اگر خراب بود اون فریم رو به عنوان یک Corrupted Frame یا یک فریم خراب تشخیص میده و توسط سوییچ Drop میشه .
میتونم بگم که روش Store and forward روش خوبیه چرا که فریم ها بررسی میشن و در صورت خراب بودن توسط سوییچ سریعا Drop میشن و فریم به مقصد ارسال نمیشه و مشکل این روش سرعت پایینشه ؟؟
دلیل این سرعت پایین هم اینه که بررسی کد CRC از یک طرف و خواندن Source mac و Destination mac از طرف دیگر بار زیادی رو روی پردازنده تحمیل میکنه ...
این نوع از سوییچ ها سه یا چهار بایت اول یک بسته رو میخونند تا بالاخره آدرس مقصد رو پیدا کنن سپس بسته رو به اون بخش یا سگمنتی که ادرس مقصد بسته رو داره ارسال میکنن و بقیه قسمت های باقی مانده رو ار نظر خطایابی مورد بررسی قرار نمی دهند .
این نوع سوییچ ها ، به محض دریافت بسته ، سریعا Mac Address بسته رو می خونن و اون 6 بایت آدرس MAC رو ذخیره میکنن و در حالتی که بقیه بسته ها در حال رسیدن به سوییچ هستن ، بسته ای که بررسی کرده رو به سمت نود مقصد ارسال میکنه .
در این نوع Switching فقط قسمت های اولیه فریم که شامل Preamble و آدرس MAC گیرنده می شود توسط دستگاه چک میشه و فریم سریعا به مقصد خودش هدایت میشه
خوبیه این روش نسبت به حالت Store and forward اینه که سرعت بالا تری داره و مشکل این روش یا بهتر بگم نقظه ضعف این روش احتمال فرستاده شدن فریم های بد به مقصد های مورد نظر هستش زیرا که CRC فریم مورد اندازه گیری واقع نمیشه .
خیلی از شرکت های تولید کننده میان یک سری امکانات رو بر روی دستگاه اضافه میکنن (یعنی چی ؟)
به این صورت که دستگاه در کنار استفاده از روش Cut through ، اقدام به اندازه گیری CRC فریم هم میکنه و تعداد فریم های مشکل دار رو در حافظه خودش نگه میداره سپس اگر این فریم های بد از حدی پیشرفت کردن به صورت خودکار عمل switching به Store and forward تبدیل میشه که بهش Dynamic Switching نیز میگویند .
این نوع از سوئیچینگ هم مانند Cut through عمل میکنه با این تفاوت که در این روش قبل از اینکه بسته ارسال شود 64 بایت اول که شامل preamble , MAC هستش رو نگه میدارن این کار به این دلیل بیشتر خطاها و برخورد ها در طول اولین 64 بایت بسته اطلاعاتی اتفاق می افتد .
با توجه به این موضوع که اندازه فریم های Ethernet حداقل 64 بایت است ، استفاده از Fragment Free روش بهتری برای عمل Switching هست .هدف از این روش Fragmnet Free کاهش فریم هایی هست که کمتر از 64 بایت بوده که این نوع فریم ها runt نامیده میشوند و به قولی به این روش Runtless هم می گویند .
در این روش نیز باز هم مانند Cut Through فریم های بد توسط دستگاه عبور داده می شوند که با فن Dynamic Switching میشه این مشکل رو تا حدی برطرف کرد .
این نکته هم خالی از لطف نیست که بدونید این نوع عمل سوئیچینگ در افزایش عملکرد دستگاه به تنهایی موثر نیست و فاکتور های دیگری نیز مانند امکانات و performance دستگاه نیز باید مورد توجه قرار بگیره ...
برچسب های مهم
امروزه روش های زیادی برای جلوگیری از بارداری چه قبل از رابطه جنسی و چه بعد از آن وجود دارد؛ اما با توجه به بی تجربگی زوج های جوان موارد زیادی با بارداری ناخواسته منجر می شود؛ از این رو لازم است تا زوج ها روش هایی را برای اطلاع از بارداری در سریع ترین زمان ممکن بیاموزند. در ادامه شما را با این روش ها آشنا خواهیم کرد. با دکتر سلام همراه باشید.بسیاری از بارداری های اول در زوجهای جوان به صورت ناخواسته به وجود میآید و دربرخی موارد بی اطلاعی مادر از بارداری و مصرف دارو یا مواردی از این دست سبب آسیب شدید به جنین و حتی مرگ او شده است.
به همین دلیل شناسایی نشانههای اولیه بارداری در زنان میتواند گامی مهم برای سلامت آنها و جنین و نیز برنامه ریزی دقیق برای ادامه بارداری باشد.
بارداری به دلیل ایجاد دگرگونیهای فراوان در بدن با نشانههایی همراه است، از جمله مشهور ترین نشانهها که در کوتاهترین زمان ممکن میتواند بارداری را شناسایی کند موارد زیر است.
برهم خوردن دوره طبیعی سیکل قاعدگی ماهانه در بانوان و عقب افتادن آن، افزایش درج حرارت بدن به طورناگهانی (بین چند اوش)، خستگی، افزایش ضربان قلب، انقباض شکمی، افزایش قدرت بویایی و تحمل نکردن بوی برخی مواد غذایی، افزایش وزن وافزایش قدرت شنوایی همگی از نشانههای اولیه بارداری است.
موارد فوق نشانههای بالینی مبنی بر بارداری است، اما برای شناسایی قطعی بارداری انجام آزمایش خون، کشت ادرار، استفاده از بیبی چک و انجام تصویربرداری سونوگرافی میتواند مورد استفاده قرارگیرد.
از جمله دیگر نشانههای بالینی بارداری که توجه به آنها میتواند مادر را متوجه بارداری خود کند، احساس تهوع واستفراغ درساعتهای اولیه روز است که به نام ویاربارداری شناخته میشود، اسهال و دل پیچه، دگرگونی خلقی، لکه بینی، بالارفتن فشارخون، سوزش سر دل، افزایش ضربان قلب، بروز آکنه و جوش صورت که درصورت بروز این نشانهها مادر برای اطمینان از باردار بودن باید از روشهای تشخیصی دقیق استفاده کند.
یکی از خطرناکترین عارضههایی که جنین را تهدید میکند ناآگاهی مادر از بارداری و انجام کارهایی، چونن مصرف دارو به ویژه داروهای اعصاب و روان، مسکن و آنتی بیوتیک، سوار شدن برهواپیما، داشتن استرس شدید، بلند کردن وسیلههای سنگین، مصرف سیگار، انجام جراحی یا تزریق ژل و بوتاکس، استفاده از برخی داروهای موضعی و مصرف برخی مواد غذایی ناسالم است.
nausea
بسیاری از مادران پس از مدتی با مشاهده خونریزی به پزشک مراجعه میکنند و متوجه سقط جنین ناخواسته میشوند درصورتی که اگر از روزهای اولیه بارداری خود را تشخیص میدادند جنین آنها زنده میماند.
احساس تکرر ادرار نیز یکی دیگر از نشانههای بارداری در بانوان است، زیرا به دلیل افزایش وزن جنینن فشاربر کلیه افزایش پیدا کرده و به دنبال آن مادر بیشتر نیاز به تخلیه ادرار پیدا میکند.
یبوست نیز یکی دیگر از نشانههای اولیه بارداری است و برای رفع آن مادر باید در رژیم غذایی خود مصرف میوه و سبزیهای تازه، مایعات و لبنیات را قراردهد. زیرا گرفتگی روده در موارد نادر ناشی از یبوست میتواند سبب سقط جنین شود.
احساس سوزش سر دل نیز نشانه دیگری از بارداری است که به دلیل دگرگونیهای هورمونی و اسیدیی شدن معده رخ میدهد، برای تسکین این حالت مصرف مواد غذایی در چندین نوبت به جای سه وعده اصلی و نوشیدن شیر میتواند راه گشا باشد.
کارشناسان به بانوان متاهل توصیه میکنند حتی درصورت استفاده از روشهای پیشگیری همیشه بهه طور منظم تست بارداری انجام دهند تا از وضعیت خود اطمینان پیدا کنند.
دستگاه بیبی چک یک وسیله با قیمت مناسب و در دسترس است که میتواند به راحتی در خانه توسط مادر مورد استفاده قرار گیرد و با درصد بالایی باردار بودن یا نبودن را به او و خانواده اطلاع دهد.
منبع: راهنمای سفر من
برچسب های مهم
متن کاوی فناوری ایجاد شده جهت کنترل داده های متنی در حال رشد است که در جهت برچینی اطلاعات معنی دار از متون زبان طبیعی تلاش می کند. متن کاوی یعنی جستجوی الگوها در متن غیرساخت یافته و برای کشف خودکار دانش مورد علاقه یا مفید از متن نیمه ساخت یافته استفاده می-شود [Tan 2005].
متن کاوی تقریبا معادل با تجزیه و تحلیل متون است که وظیفه آن استخراج اطلاعات با کیفیت بالا از متن می باشد [Kan 2007]. در موارد معدودی نیز به عنوان فرآیند تحلیل متن جهت استخراج اطلاعاتی که برای اهداف خاصی مفید هستند، تعریف می شود. در زمینه کاوش متن معمولا با متونی مواجه هستیم که وظیفه آنها ارتباط اطلاعات حقیقی و یا عقاید می باشد و هدف آن استخراج خودکار اطلاعات از چنین متونی می باشد، هر چند موفقیت جزئی حاصل گردد [Kan 2007].
به طور کلی متن کاوی جهت مشخص کردن سیستمی که بتواند حجم زیادی از متون زبان طبیعی را تحلیل کند و الگوهای مفید زبانی و لغوی را شناسایی کرده و به دنبال آن اطلاعات احتمالا مفید را استخراج کند، استفاده می شود [Fan 2005]. شکل ۱-۱ یک مدل کلی از یک کاربرد متن کاوی را نشان می دهد. این مدل با مجموعه ای از اسناد شروع می شود، یک ابزار متن کاوی، یک سند خاص را بازیابی و پیش پردازش می کند. سپس یک مرحله تحلیل متن انجام شده و در مواقعی از شیوه-های مکرر تا استخراج اطلاعات استفاده می شود. سه روش تحلیل متن در این نمونه نشان داده شده اما بسیاری از ترکیبات دیگر نیز بر اساس اهداف سازماندهی می توانند استفاده شوند. اطلاعات حاصل می تواند در یک سیستم مدیریت اطلاعات قرار داده شود و در نهایت حجم وسیعی از دانش برای کاربر آن سیستم فراهم می شود [Fan 2005].
گاهی به جای واژه متن کاوی از عبارت “کشف دانش از متن” (KDT )، استفاده می شود [Sha 2005]. معمولا وظایف متن کاوی شامل طبقه بندی متن، خوشه بندی متن ، استخراج مفهوم، تحلیل معنایی، خلاصه سازی متن و مدل سازی روابط میان نهادها می باشد .
خوشه بندی، روش داده کاوی قدرتمندی است که جهت کشف موضوع از اسناد متنی مورد استفاده قرار می گیرد. در این زمینه الگوریتم های خانواده k-means به دلیل سادگی و سرعت بالا، در خوشه بندی داده هایی با ابعاد بالا، کاربرد فراوانی دارند. در این الگوریتم ها، معیار شباهت cosine، تنها شباهت میان زوج اسناد را اندازه گیری می کند که در مواقعی که خوشه ها به خوبی تفکیک نشده باشند، عملکرد مناسبی ندارد. درمقابل، مفاهیم همسایگی و اتصال با در نظرگرفتن اطلاعات سراسری در محاسبه میزان نزدیکی دو سند، عملکرد بسیار بهتری دارند. چنانچه میزان شباهت دو سند از حد آستانه ای بیشتر باشد آن دو سند همسایه اند و تعداد همسایه های مشترک میان آنها، مقدار تابع اتصال این دو سند را نشان می دهد. بنابراین با توجه به اینکه تنها دو حالت همسایگی و عدم همسایگی داریم که با صفر و یک نمایش داده می شوند، مقداری از اطلاعات را در مورد میزان شباهت میان اسناد از دست می دهیم که منجر به کاهش دقت خوشه بندی حاصل می شود. جهت رفع این مشکل، در گام اول لیستی از مقادیر گسسته را برای تعیین بازه ای از مقادیر آستانه به جای تنها یک مقدار، در نظر گرفتیم که به دنبال آن درجات متفاوتی از همسایگی، بر اساس میزان شباهت میان اسناد خواهیم داشت. همچنین جهت افزایش هر چه بیشتر دقت نتایج حاصل، از منطق فازی نیز بهره برده و مقدار شباهت میان اسناد را با استفاده از مقادیر عضویت فازی نمایش دادیم. به این ترتیب میزان همبستگی میان اسناد را با استفاده از منطق فازی بهبود داده و گام جدیدی در کاربردهای منطق فازی برداشتیم.
همچنین در این مدل، روابط معنایی میان کلمات نادیده گرفته شده و تنها اسنادی با واژگان مشابه با یکدیگر مرتبط شده اند. در این پروژه پایانی از آنتولوژی WordNet جهت ایجاد مدل جدید نمایش اسناد بهره بردیم، بدین صورت که در آن از روابط معنایی به منظور وزن گذاری مجدد بسامد کلمات در مدل فضای برداری اسناد استفاده شده است. سپس مفاهیم همسایگی و اتصال را بر روی مدل حاصل اعمال نمودیم. نتایج حاصل از اعمال روش های پیشنهادی و ترکیبات آنها بر روی مجموعه داده های متن واقعی، حاکی از عملکرد موثر و مناسب تر الگوریتم پیشنهادی ما نسبت به روش های پیشین می-باشد و می تواند جایگزین خوبی برای الگوریتم های پیشین در امر خوشه بندی اسناد باشد.
تقلب شامل طیف وسیعی ازشیوهها، ورود اطلاعات نادرست واعمال غیرقانونی است که دریک سازمان میتواند اثرات بسیارسوء مالی وروانی به همراه داشته باشد.حتی اتهام تقلب به تنهایی کافی است تا خسارت چشمگیر به شهرت و همچنین روابط مشتری و کارفرما واردکند.با توجه به این مسائل برای هر سازمان بسیارحائز اهمیت است که یک سیستم مدیریت تقلب داشته باشد. تکنولوژی روشهای گوناگونی برای جلوگیری ازتقلب طراحی وارائه نموده است که یکی از بهترین روشهای ارائه شده استفاده از تکنیک دادهکاوی است.مابا طبقهبندی مناسب اطلاعات به روش دادهکاوی میتوانیم تقلب در همه سطوح از جمله شبکه های اجتماعی را تشخیص و یاپیشبینی کنیم.
واژههايكليدي
تقلب،انباره داده،دادهکاوی،سیستم تشخیص تقلب،پایگاه دانش.

برچسب های مهم
مطالب تصادفی