اگر به یک وب سایت یا فروشگاه رایگان با فضای نامحدود و امکانات فراوان نیاز دارید بی درنگ دکمه زیر را کلیک نمایید.
ایجاد وب سایت یادسته بندی سایت
محبوب ترین ها
پرفروش ترین ها
پر فروش ترین های فورکیا
پر بازدید ترین های فورکیا
 آموزش ساخت بازی بدون دانش برنامه نویسی و طراحی سه بعدی مبتدی تا پیشرفته با نرم افزار
آموزش ساخت بازی بدون دانش برنامه نویسی و طراحی سه بعدی مبتدی تا پیشرفته با نرم افزار دانلود100% رایگان نرم افزار تبلیغات در تلگرام + آموزش کامل و فیلم آموزشی
دانلود100% رایگان نرم افزار تبلیغات در تلگرام + آموزش کامل و فیلم آموزشی کاغذ میلیمتری
کاغذ میلیمتری آموزش افزایش لایک و فالوور واقعی اینستاگرام در اندروید و iOS به صورت نامحدود
آموزش افزایش لایک و فالوور واقعی اینستاگرام در اندروید و iOS به صورت نامحدود اینترنت اشیا-پاورپوینت Internet of Things (IoT) -powerpoint
اینترنت اشیا-پاورپوینت Internet of Things (IoT) -powerpoint آپلود بالا 2 دقیقه اینستاگرام برای اولین بار در فروشگاه دیجی دانلود
آپلود بالا 2 دقیقه اینستاگرام برای اولین بار در فروشگاه دیجی دانلود جلوگیری از هک وای فای + آموزش و نرم افزار
جلوگیری از هک وای فای + آموزش و نرم افزار کتاب راهنمای گام به گام بازی جی تی آی 5 Gta San Andreas
کتاب راهنمای گام به گام بازی جی تی آی 5 Gta San Andreas گام به گام نهم
گام به گام نهم آپدیت پایونیر 7950
آپدیت پایونیر 7950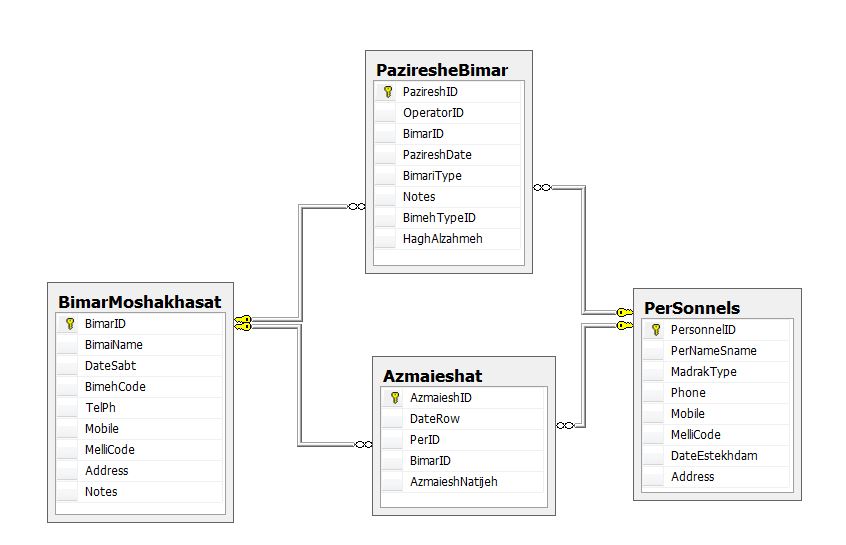 طراحی پایگاه داده مطب پزشک به همراه نمودار ER
طراحی پایگاه داده مطب پزشک به همراه نمودار ER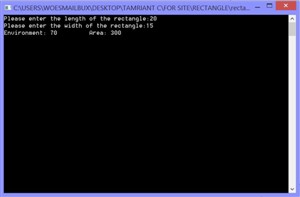 برنامه محاسبه محیط و مساحت مستطیل
برنامه محاسبه محیط و مساحت مستطیل دانلود ارزان کتاب نایاب و گران قیمت (Security+ Guide to Network Security Fundamentals (Cyber Security
دانلود ارزان کتاب نایاب و گران قیمت (Security+ Guide to Network Security Fundamentals (Cyber Security آموزش دانلود و ذخیره تمام موزیک های Spotify در کامپیوتر با فرمت MP3
آموزش دانلود و ذخیره تمام موزیک های Spotify در کامپیوتر با فرمت MP3 ICDL2 - سوال کتبی ( سری اول )
ICDL2 - سوال کتبی ( سری اول ) دانلود کتاب کمیاب SQL Injection Attacks and Defense, Second Edition
دانلود کتاب کمیاب SQL Injection Attacks and Defense, Second Edition دانلود کتاب TCPIP Analysis ویژه مدرسین و کسانی که میخواهند TCP IP را مفهومی فراگیری کنند
دانلود کتاب TCPIP Analysis ویژه مدرسین و کسانی که میخواهند TCP IP را مفهومی فراگیری کنند دانلود کتاب آموزش برنامه نویسی Perl
دانلود کتاب آموزش برنامه نویسی Perl دانلود کتاب کاربردی Runnig Linux
دانلود کتاب کاربردی Runnig Linux دانلود اپرا رایگان برای اندروید جدید و سالم
دانلود اپرا رایگان برای اندروید جدید و سالم سوالات مهم در امتحان مهارت های هفت گانه ICDL
سوالات مهم در امتحان مهارت های هفت گانه ICDL دانلود کتاب Python Testing Cookbook
دانلود کتاب Python Testing Cookbook آموزش باز کردن قفل پترن PATTERN گوشی اندروید
آموزش باز کردن قفل پترن PATTERN گوشی اندروید دانلود کتاب فوق العاده کمیاب و گران قیمت Stealing the Network: How to Own the Box
دانلود کتاب فوق العاده کمیاب و گران قیمت Stealing the Network: How to Own the Box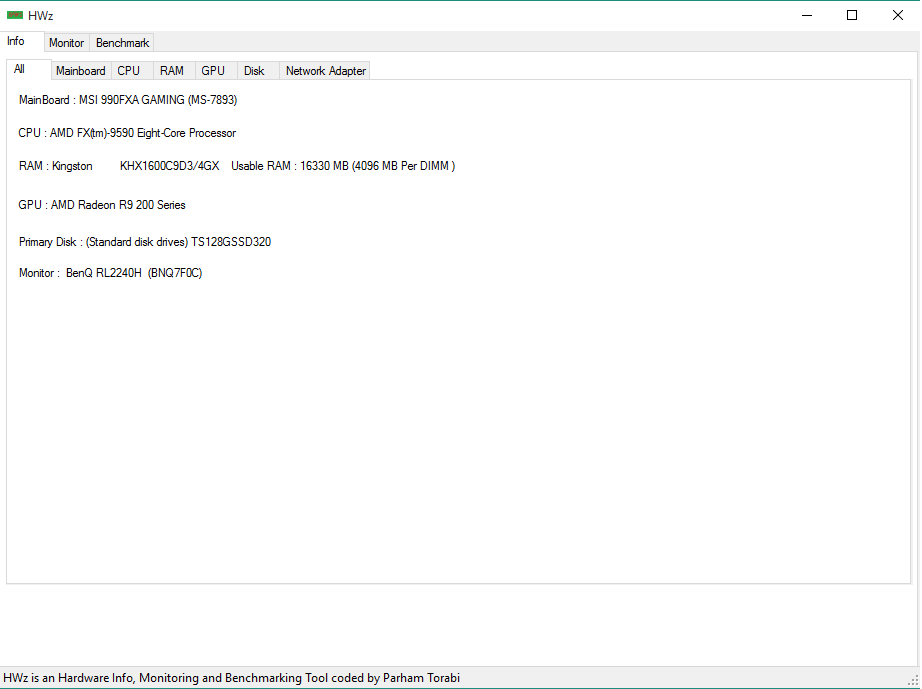 HWz
HWz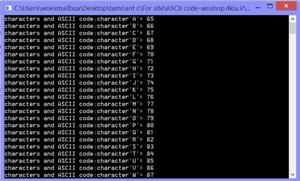 برنامه چاپ کاراکترهای A تا z به همراه کد اسکی آنها
برنامه چاپ کاراکترهای A تا z به همراه کد اسکی آنها پروتکل IPTV مطالعه معماری و پیاده سازی (تخفیف 80% به مدت پنج روز)
پروتکل IPTV مطالعه معماری و پیاده سازی (تخفیف 80% به مدت پنج روز) ICDL2 - سوال کتبی ( سری سوم )
ICDL2 - سوال کتبی ( سری سوم ) دانلود نرم افزار پیدا کردن وبلاگ های رنک دار حذف شده (پیدا کنید بفروشید کسب درآمد کنید)
دانلود نرم افزار پیدا کردن وبلاگ های رنک دار حذف شده (پیدا کنید بفروشید کسب درآمد کنید)برچسب های مهم
پیوند ها
متن کاوی فناوری ایجاد شده جهت کنترل داده های متنی در حال رشد است که در جهت برچینی اطلاعات معنی دار از متون زبان طبیعی تلاش می کند. متن کاوی یعنی جستجوی الگوها در متن غیرساخت یافته و برای کشف خودکار دانش مورد علاقه یا مفید از متن نیمه ساخت یافته استفاده می-شود [Tan 2005].
متن کاوی تقریبا معادل با تجزیه و تحلیل متون است که وظیفه آن استخراج اطلاعات با کیفیت بالا از متن می باشد [Kan 2007]. در موارد معدودی نیز به عنوان فرآیند تحلیل متن جهت استخراج اطلاعاتی که برای اهداف خاصی مفید هستند، تعریف می شود. در زمینه کاوش متن معمولا با متونی مواجه هستیم که وظیفه آنها ارتباط اطلاعات حقیقی و یا عقاید می باشد و هدف آن استخراج خودکار اطلاعات از چنین متونی می باشد، هر چند موفقیت جزئی حاصل گردد [Kan 2007].
به طور کلی متن کاوی جهت مشخص کردن سیستمی که بتواند حجم زیادی از متون زبان طبیعی را تحلیل کند و الگوهای مفید زبانی و لغوی را شناسایی کرده و به دنبال آن اطلاعات احتمالا مفید را استخراج کند، استفاده می شود [Fan 2005]. شکل ۱-۱ یک مدل کلی از یک کاربرد متن کاوی را نشان می دهد. این مدل با مجموعه ای از اسناد شروع می شود، یک ابزار متن کاوی، یک سند خاص را بازیابی و پیش پردازش می کند. سپس یک مرحله تحلیل متن انجام شده و در مواقعی از شیوه-های مکرر تا استخراج اطلاعات استفاده می شود. سه روش تحلیل متن در این نمونه نشان داده شده اما بسیاری از ترکیبات دیگر نیز بر اساس اهداف سازماندهی می توانند استفاده شوند. اطلاعات حاصل می تواند در یک سیستم مدیریت اطلاعات قرار داده شود و در نهایت حجم وسیعی از دانش برای کاربر آن سیستم فراهم می شود [Fan 2005].
گاهی به جای واژه متن کاوی از عبارت “کشف دانش از متن” (KDT )، استفاده می شود [Sha 2005]. معمولا وظایف متن کاوی شامل طبقه بندی متن، خوشه بندی متن ، استخراج مفهوم، تحلیل معنایی، خلاصه سازی متن و مدل سازی روابط میان نهادها می باشد .
خوشه بندی، روش داده کاوی قدرتمندی است که جهت کشف موضوع از اسناد متنی مورد استفاده قرار می گیرد. در این زمینه الگوریتم های خانواده k-means به دلیل سادگی و سرعت بالا، در خوشه بندی داده هایی با ابعاد بالا، کاربرد فراوانی دارند. در این الگوریتم ها، معیار شباهت cosine، تنها شباهت میان زوج اسناد را اندازه گیری می کند که در مواقعی که خوشه ها به خوبی تفکیک نشده باشند، عملکرد مناسبی ندارد. درمقابل، مفاهیم همسایگی و اتصال با در نظرگرفتن اطلاعات سراسری در محاسبه میزان نزدیکی دو سند، عملکرد بسیار بهتری دارند. چنانچه میزان شباهت دو سند از حد آستانه ای بیشتر باشد آن دو سند همسایه اند و تعداد همسایه های مشترک میان آنها، مقدار تابع اتصال این دو سند را نشان می دهد. بنابراین با توجه به اینکه تنها دو حالت همسایگی و عدم همسایگی داریم که با صفر و یک نمایش داده می شوند، مقداری از اطلاعات را در مورد میزان شباهت میان اسناد از دست می دهیم که منجر به کاهش دقت خوشه بندی حاصل می شود. جهت رفع این مشکل، در گام اول لیستی از مقادیر گسسته را برای تعیین بازه ای از مقادیر آستانه به جای تنها یک مقدار، در نظر گرفتیم که به دنبال آن درجات متفاوتی از همسایگی، بر اساس میزان شباهت میان اسناد خواهیم داشت. همچنین جهت افزایش هر چه بیشتر دقت نتایج حاصل، از منطق فازی نیز بهره برده و مقدار شباهت میان اسناد را با استفاده از مقادیر عضویت فازی نمایش دادیم. به این ترتیب میزان همبستگی میان اسناد را با استفاده از منطق فازی بهبود داده و گام جدیدی در کاربردهای منطق فازی برداشتیم.
همچنین در این مدل، روابط معنایی میان کلمات نادیده گرفته شده و تنها اسنادی با واژگان مشابه با یکدیگر مرتبط شده اند. در این پروژه پایانی از آنتولوژی WordNet جهت ایجاد مدل جدید نمایش اسناد بهره بردیم، بدین صورت که در آن از روابط معنایی به منظور وزن گذاری مجدد بسامد کلمات در مدل فضای برداری اسناد استفاده شده است. سپس مفاهیم همسایگی و اتصال را بر روی مدل حاصل اعمال نمودیم. نتایج حاصل از اعمال روش های پیشنهادی و ترکیبات آنها بر روی مجموعه داده های متن واقعی، حاکی از عملکرد موثر و مناسب تر الگوریتم پیشنهادی ما نسبت به روش های پیشین می-باشد و می تواند جایگزین خوبی برای الگوریتم های پیشین در امر خوشه بندی اسناد باشد.

همه کسانی که در زمینه طراحی و ساخت مدارات الکترونیکی فعالیت می کنن و با مدارات آزمایشی سر و کار دارند با مسائل مربوط به استفاده از فیبر سوراخدار و مدارات چاپی آشنا هستند. معمولا برای پیاده سازی مدارات کوچک از فیبر های سوراخدار آماده موجود در بازار استفاده می کنیم. ولی زمانی ... ...
مطالب تصادفی