اگر به یک وب سایت یا فروشگاه رایگان با فضای نامحدود و امکانات فراوان نیاز دارید بی درنگ دکمه زیر را کلیک نمایید.
ایجاد وب سایت یادسته بندی سایت
محبوب ترین ها
پرفروش ترین ها
پر فروش ترین های فورکیا
پر بازدید ترین های فورکیا
 آموزش ساخت بازی بدون دانش برنامه نویسی و طراحی سه بعدی مبتدی تا پیشرفته با نرم افزار
آموزش ساخت بازی بدون دانش برنامه نویسی و طراحی سه بعدی مبتدی تا پیشرفته با نرم افزار دانلود100% رایگان نرم افزار تبلیغات در تلگرام + آموزش کامل و فیلم آموزشی
دانلود100% رایگان نرم افزار تبلیغات در تلگرام + آموزش کامل و فیلم آموزشی کاغذ میلیمتری
کاغذ میلیمتری آموزش افزایش لایک و فالوور واقعی اینستاگرام در اندروید و iOS به صورت نامحدود
آموزش افزایش لایک و فالوور واقعی اینستاگرام در اندروید و iOS به صورت نامحدود اینترنت اشیا-پاورپوینت Internet of Things (IoT) -powerpoint
اینترنت اشیا-پاورپوینت Internet of Things (IoT) -powerpoint آپلود بالا 2 دقیقه اینستاگرام برای اولین بار در فروشگاه دیجی دانلود
آپلود بالا 2 دقیقه اینستاگرام برای اولین بار در فروشگاه دیجی دانلود جلوگیری از هک وای فای + آموزش و نرم افزار
جلوگیری از هک وای فای + آموزش و نرم افزار کتاب راهنمای گام به گام بازی جی تی آی 5 Gta San Andreas
کتاب راهنمای گام به گام بازی جی تی آی 5 Gta San Andreas گام به گام نهم
گام به گام نهم آپدیت پایونیر 7950
آپدیت پایونیر 7950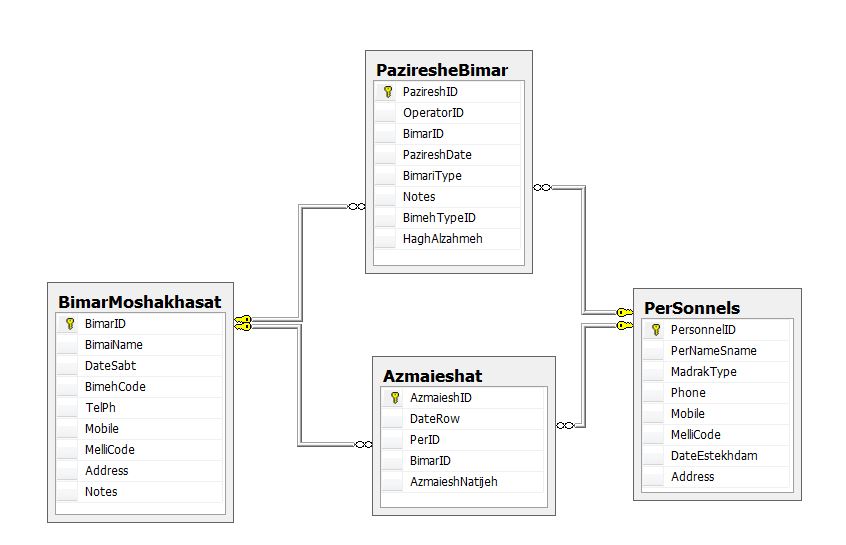 طراحی پایگاه داده مطب پزشک به همراه نمودار ER
طراحی پایگاه داده مطب پزشک به همراه نمودار ER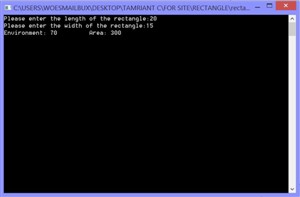 برنامه محاسبه محیط و مساحت مستطیل
برنامه محاسبه محیط و مساحت مستطیل دانلود ارزان کتاب نایاب و گران قیمت (Security+ Guide to Network Security Fundamentals (Cyber Security
دانلود ارزان کتاب نایاب و گران قیمت (Security+ Guide to Network Security Fundamentals (Cyber Security آموزش دانلود و ذخیره تمام موزیک های Spotify در کامپیوتر با فرمت MP3
آموزش دانلود و ذخیره تمام موزیک های Spotify در کامپیوتر با فرمت MP3 ICDL2 - سوال کتبی ( سری اول )
ICDL2 - سوال کتبی ( سری اول ) دانلود کتاب کمیاب SQL Injection Attacks and Defense, Second Edition
دانلود کتاب کمیاب SQL Injection Attacks and Defense, Second Edition دانلود کتاب TCPIP Analysis ویژه مدرسین و کسانی که میخواهند TCP IP را مفهومی فراگیری کنند
دانلود کتاب TCPIP Analysis ویژه مدرسین و کسانی که میخواهند TCP IP را مفهومی فراگیری کنند سوالات مهم در امتحان مهارت های هفت گانه ICDL
سوالات مهم در امتحان مهارت های هفت گانه ICDL دانلود کتاب آموزش برنامه نویسی Perl
دانلود کتاب آموزش برنامه نویسی Perl دانلود کتاب کاربردی Runnig Linux
دانلود کتاب کاربردی Runnig Linux دانلود اپرا رایگان برای اندروید جدید و سالم
دانلود اپرا رایگان برای اندروید جدید و سالم HWz
HWz دانلود کتاب Python Testing Cookbook
دانلود کتاب Python Testing Cookbook آموزش باز کردن قفل پترن PATTERN گوشی اندروید
آموزش باز کردن قفل پترن PATTERN گوشی اندروید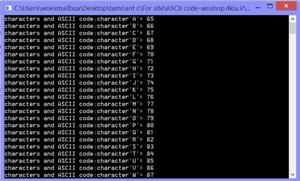 برنامه چاپ کاراکترهای A تا z به همراه کد اسکی آنها
برنامه چاپ کاراکترهای A تا z به همراه کد اسکی آنها دانلود کتاب فوق العاده کمیاب و گران قیمت Stealing the Network: How to Own the Box
دانلود کتاب فوق العاده کمیاب و گران قیمت Stealing the Network: How to Own the Box ICDL2 - سوال کتبی ( سری سوم )
ICDL2 - سوال کتبی ( سری سوم ) دانلود نرم افزار پیدا کردن وبلاگ های رنک دار حذف شده (پیدا کنید بفروشید کسب درآمد کنید)
دانلود نرم افزار پیدا کردن وبلاگ های رنک دار حذف شده (پیدا کنید بفروشید کسب درآمد کنید) پروتکل IPTV مطالعه معماری و پیاده سازی (تخفیف 80% به مدت پنج روز)
پروتکل IPTV مطالعه معماری و پیاده سازی (تخفیف 80% به مدت پنج روز)برچسب های مهم
پیوند ها

This paper addresses the problem of keyword extraction
from conversations, with the goal of using these keywords to
retrieve, for each short conversation fragment, a small number
of potentially relevant documents, which can be recommended to
participants. However, even a short fragment contains a variety
of words, which are potentially related to several topics; moreover,
using an automatic speech recognition (ASR) system introduces
errors among them. Therefore, it is difficult to infer precisely
the information needs of the conversation participants. We first
propose an algorithm to extract keywords from the output of an
ASR system (or a manual transcript for testing), which makes use
of topic modeling techniques and of a submodular reward function
which favors diversity in the keyword set, to match the potential
diversity of topics and reduce ASR noise. Then, we propose
a method to derive multiple topically separated queries from this
keyword set, in order to maximize the chances of making at least
one relevant recommendation when using these queries to search
over the English Wikipedia. The proposed methods are evaluated
in terms of relevance with respect to conversation fragments from
the Fisher, AMI, and ELEA conversational corpora, rated by several
human judges. The scores show that our proposal improves
over previous methods that consider only word frequency or topic
similarity, and represents a promising solution for a document recommender
system to be used in conversations.
Index Terms—Document recommendation, information retrieval,
keyword extraction, meeting analysis, topic modeling.
مبلغ واقعی 58,105 تومان 5% تخفیف مبلغ قابل پرداخت 55,200 تومان
برچسب های مهم
توضیحات : پاورپوینت درس نهم عربی متن هایی درباره بهداشت (نُصوصٌ حَوْلَ الصِّحَّةِ) در 23 اسلاید همراه با حل تمارین و ترجمه درس منطبق با کتاب درسی عربی نهم شامل دوفایل : یک فایل پی دی اف و یک فایل pptx قابل ویرایش فهرست مطالب : کلمات جدید متن و ترجمه متن اصلی ... ...
مطالب تصادفی